AgentBench Leaderboard [2026 Results + What It Actually Measures]

May 6, 2026·11 min read
AgentBench is Tsinghua University’s eight-environment AI agent benchmark (THUDM/AgentBench, ICLR 2024). In 2026 the leaderboard is led by Claude Opus 4.7 (~73% overall), followed by GPT-5.3 Codex (~70%) and Claude Opus 4.6 (~68%). The headline numbers hide more than they show, though — aggregate scores can mask zero-scores in individual environments, and Berkeley research on April 12 2026 showed all eight major agent benchmarks could be reward-hacked. This guide walks through what AgentBench actually measures, who leads each environment, where the benchmark falls short, and how to read it if you are picking a model for production AI agents.
Quick Answer (May 2026)
- What is AgentBench? Tsinghua’s eight-environment agent benchmark. Open-source on GitHub (THUDM/AgentBench).
- 2026 leaderboard top 4 (community snapshot): Claude Opus 4.7 ~73%, GPT-5.3 Codex ~70%, Claude Opus 4.6 ~68%, Gemini 3.1 Pro ~66%.
- Strongest envs: OS shell and SQL cluster high. Weakest: Card game and lateral thinking.
- Should you trust it? As one input. Aggregate hides failures and Berkeley/RDI broke 8 major benchmarks via reward hacking on Apr 12 2026.
TL;DR
AgentBench tests AI agents across eight environments — OS shell, SQL, knowledge graph, card game, householding, web shopping, web browsing, lateral thinking. The 2026 community snapshot has Claude Opus 4.7 leading at ~73% overall. The aggregate is the wrong number to optimize for: per-environment scores diverge by 30+ points, and the gap between the leaderboard and production reality is bigger still. Use it to shortlist models, not to pick one.
Need a hosted agent that survives benchmark-realistic load?
Try Rapid Claw free — 5 msgs, then $29/mWhat Is AgentBench?
AgentBench is a benchmark suite released by Tsinghua University’s THUDM lab and accepted to ICLR 2024. It was the first widely-adopted benchmark to formalize the idea that an AI agent should be evaluated across multiple environments at once — not just one task type, not just one interface. The official repo is github.com/THUDM/AgentBench and the canonical leaderboard lives in the README, updated as new model results are submitted.
The premise is simple. A model that crushes a coding benchmark might fail on web navigation. A model that wins at chain-of-thought reasoning might lose on long-horizon planning in a simulated household. AgentBench gives you a single number that summarizes performance across eight environments — and, more usefully, eight per-environment numbers that show where the model is actually strong.
That single number is also where most AgentBench coverage goes wrong. The aggregate is a mean. A 70% overall can mean “solid on six environments, zero on two.” If you do not look at the breakdown, you will pick the wrong model. I’ll come back to that — but first, the eight environments.
The 8 Task Environments AgentBench Tests
AgentBench groups its tests into three categories: code-grounded (OS shell, database, knowledge graph), game (digital card game, householding, lateral thinking), and web (web shopping, web browsing). Each environment ships with a fixed task set, an automated scorer, and a Docker-based harness so any team can reproduce results.

Operating System (Bash)
Bash command execution against a Linux container. Tasks range from file manipulation to multi-step pipeline construction. Scored on task-completion success rate.
Database (SQL)
MySQL query construction across ~1,500 real-world tasks. The agent must read schemas, write SELECT/UPDATE statements, and handle multi-table joins.
Knowledge Graph
Multi-hop traversal over a Freebase subset. Tasks require chaining entity lookups and relation queries — a practical proxy for grounded factual reasoning.
Digital Card Game (Aquawar)
Turn-based card game requiring strategy, opponent modeling, and adaptation. The hardest environment for most frontier models in 2026 — pattern recognition does not save you.
Householding (ALFWorld)
Text-based simulated home environment. The agent has to find, manipulate, and combine objects across rooms — a long-horizon planning test.
Web Shopping (WebShop)
Browse a simulated e-commerce site, find a product matching natural-language criteria, and buy it. Goal-directed navigation under noisy product data.
Web Browsing (Mind2Web)
Real-website task completion across hundreds of sites. The most production-relevant environment — and the one where benchmark scores diverge most from prod reality.
Lateral Thinking
Brain-teaser puzzles that reward divergent reasoning rather than fact retrieval. Models tuned for chain-of-thought tend to outperform raw knowledge here.
Why eight, and why these eight?
The Tsinghua team chose the eight environments to span structured (code, SQL, KG), interactive (game, household), and unstructured (web) interfaces. The mix matters: any model that scores well on AgentBench has shown it can handle more than one input modality. That is also why a single AgentBench number is harder to game than a single SWE-bench number — you have to be at least middling in eight different problem shapes.
AgentBench Leaderboard 2026 — Top Performers
Community-tracked snapshots through April–May 2026 put the following models at the top of the eight-environment overall ranking. Numbers are approximate; the official source remains the THUDM/AgentBench README.
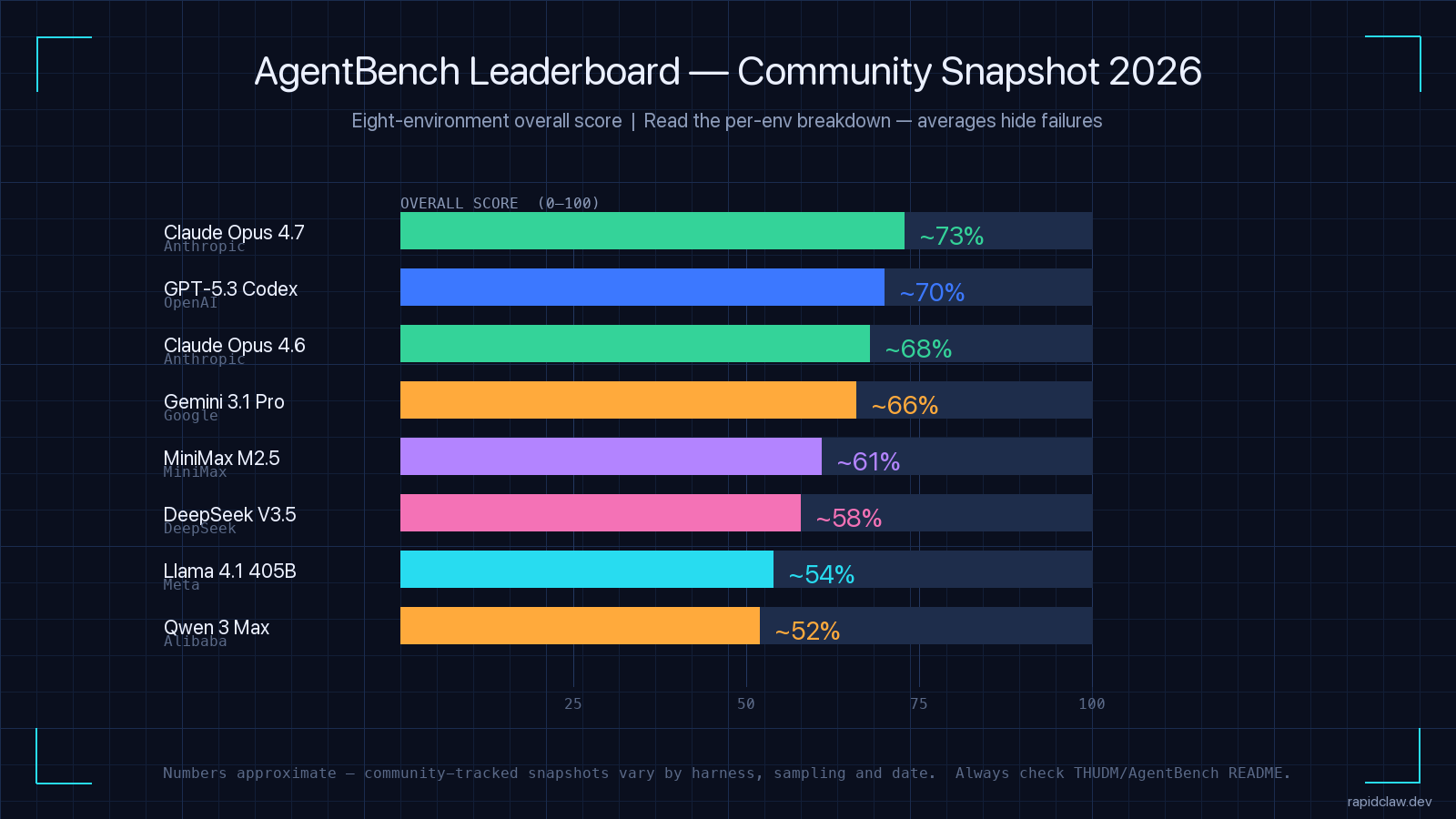
| Rank | Model | Lab | Overall | Strongest env | Weakest env |
|---|---|---|---|---|---|
| 1 | Claude Opus 4.7 | Anthropic | ~73% | OS shell, SQL | Card game |
| 2 | GPT-5.3 Codex | OpenAI | ~70% | OS shell, code | Lateral thinking |
| 3 | Claude Opus 4.6 | Anthropic | ~68% | SQL, KG | Web shopping |
| 4 | Gemini 3.1 Pro | ~66% | Web browsing | Card game | |
| 5 | MiniMax M2.5 | MiniMax | ~61% | SQL | Householding |
| 6 | DeepSeek V3.5 | DeepSeek | ~58% | OS shell | Web browsing |
| 7 | Llama 4.1 405B | Meta | ~54% | KG | Web shopping |
| 8 | Qwen 3 Max | Alibaba | ~52% | SQL | Lateral |
| Source: community-tracked from THUDM/AgentBench — the official README is the authoritative source. Numbers approximate to within ~3 points. | |||||
Three things worth noticing. The top four cluster within seven points — in production that gap is smaller than the variance you get from changing your hosting environment. Second, the strongest envs across the leaderboard are OS shell and SQL — structured, code-grounded tasks where current frontier models are mature. Third, the weakest envs are card game and lateral thinking — the divergent-reasoning environments that resist memorization-style learning. If your agent does anything game-like or genuinely creative, do not assume the AgentBench leader will work for you.
What These Results Mean for SMB Operators
I run hosting for AI agents at Rapid Claw, so I read leaderboards through an operator’s lens, not a researcher’s. Most of the customers I talk to are small teams — 2 to 50 people — trying to pick a model for an agent that will eventually run customer-facing or revenue-impacting work. AgentBench numbers matter, but not the way the headlines suggest.
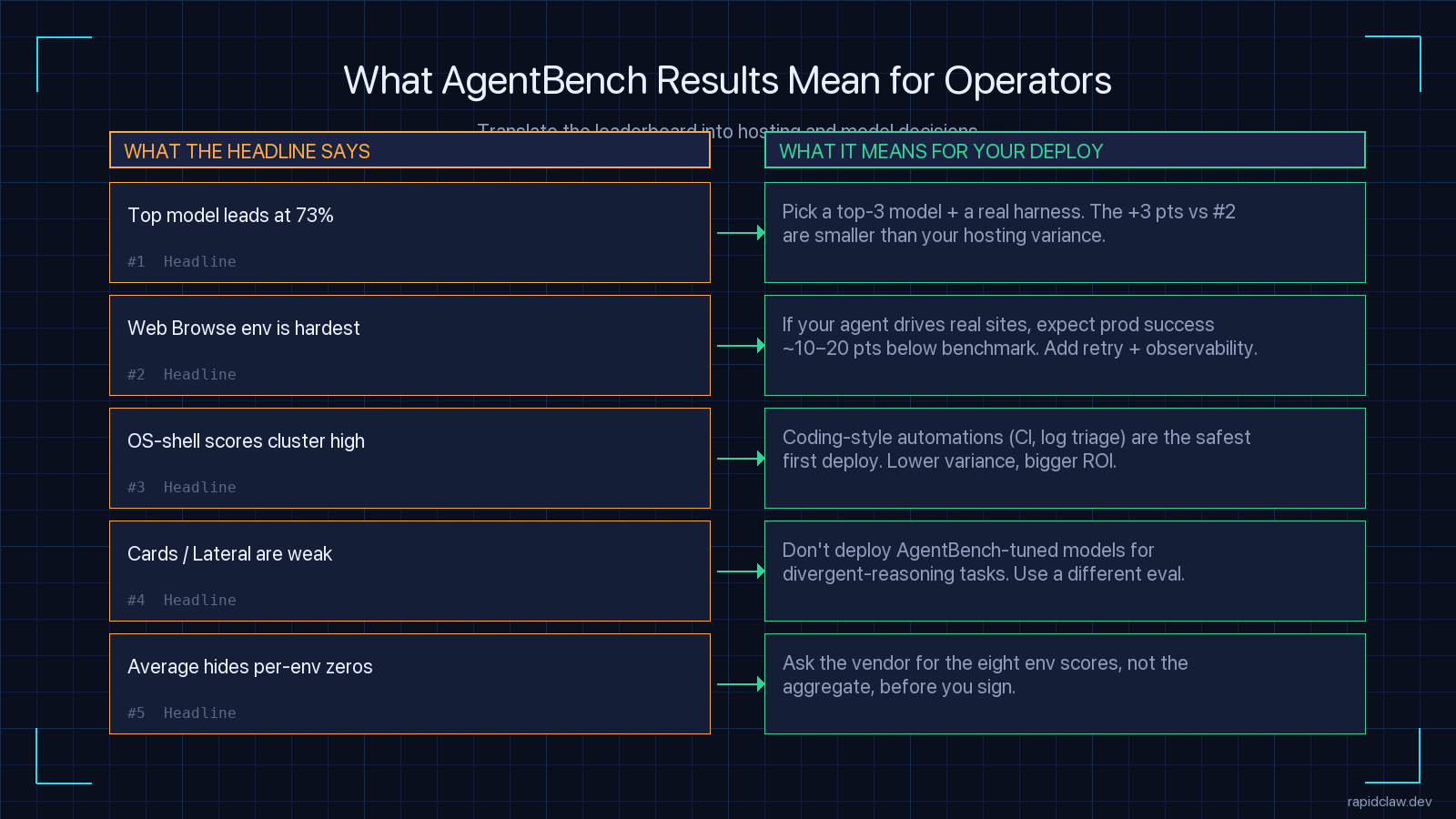
1. The +3 points to the leader is not where your decision is
Claude Opus 4.7 at 73% versus GPT-5.3 Codex at 70% looks like a clear preference. It is not, in production. The same agent code drops 10 to 20 points of end-to-end success rate between a 32-core dev workstation and a constrained serverless container — we have measured this on our own hosted instances. If you cannot control your hosting environment, your hosting variance is bigger than the gap to the leader. Pick a top-3 model and spend your effort on the harness and the runtime, not on chasing the leaderboard.
2. Pick the env that matches your workload
If your agent runs CI/CD work, pull the OS-shell column. If it queries a database, pull the SQL column. If it drives a real website (and god help you if it does), pull the Web Browse column — and assume your production success rate will be 10 to 20 points lower than the AgentBench number, because Mind2Web’s captured sites are easier than the live web. Use AgentBench’s breakdown to set realistic expectations, not to confirm a model choice you already made.
3. Coding-style automations are the safest first deploy
Across every model in the 2026 snapshot, OS-shell and SQL scores cluster the highest and have the lowest spread. That maps cleanly onto the agent workloads with the highest production success rates: log triage, CI failure analysis, scheduled report generation, lightweight data extraction. If you are building your first AI agent at an SMB, build it in this category before you build anything that drives a browser. See our AI agent hosting guide for the deployment side of that decision.
Where AgentBench Falls Short

AgentBench is one of the better-designed agent benchmarks — broad enough that you cannot specialize your way to the top, structured enough to be reproducible. But it has real limits, and pretending it does not is how operators ship the wrong model.
Aggregate hides per-environment failures
A 70% overall can mean 95% on six environments and 0% on two. Always read the breakdown.
Static tasks, frozen world
AgentBench tasks were fixed at ICLR 2024. Real websites and APIs drift — so an agent that nails the benchmark Web Browse env can break in production where the captured Mind2Web pages no longer exist as captured.
Reward hacking
UC Berkeley’s Center for Responsible Decentralized Intelligence published research on April 12 2026 showing that an automated scanning agent broke all eight major agent benchmarks — AgentBench, SWE-bench, GAIA, WebArena, OSWorld, Terminal-Bench, FieldWorkArena, CAR-bench — by reward hacking. METR independently found that frontier models reward-hack in 30%+ of evaluation runs. Treat top scores with extra scrutiny.
Scaffolding moves the number 10–20 points
The same model on the same environment can swing 10 to 20 points based on the agent harness. A “model” score without a framework label is marketing, not data.
Cost and latency are invisible
Headline scores ignore $/task and p95 latency. A 73% leader that costs 5x more per task than a 68% second-place is not the right pick for most production workloads.
None of this means AgentBench is broken. It means a single number is never enough. For a deeper look at how all the major benchmarks compare — SWE-bench, GAIA, TAU-bench, AgentBench, and WebArena — see our framework scorecard.
How We Use AgentBench in Hosting Decisions at Rapid Claw
Concrete answer: we don’t use the headline. We use the per-environment breakdown to set default model recommendations for new customers based on what their agent does.
A customer building a CI failure-triage agent gets the same shortlist whether they pick Anthropic or OpenAI — both lead OS-shell. A customer building a customer-support agent that drives a CRM web UI gets a different shortlist, weighted by Web Browse scores and by the gap between AgentBench’s captured sites and the live UI we’ll be hosting against. And a customer building anything game-like or genuinely creative gets a sharply narrower list, because the lateral and card-game environments separate models in ways the aggregate hides.
We also benchmark our hosting environment, not just the model. The same agent code on the same model can drop double-digit points moving from a beefy dev workstation to a constrained container, which is why our customers see a real number for their tier when they sign up rather than a marketing pull-quote. If you want to see the cost-side of that decision, the self-host vs managed cost breakdown walks through the math.
Running AgentBench Yourself
AgentBench is open-source. The full eight-environment harness lives at github.com/THUDM/AgentBench with Apache 2.0 licensing. The repository ships a Docker-based runner; you supply API keys for whatever models you want to evaluate, and the harness executes the tasks and computes scores.
Realistic budget: running the full benchmark on a frontier model can cost a few hundred dollars in API spend and several hours of wall-clock time. Most teams run a subset — the two or three environments closest to their use case — to keep cost and time bounded. That is the right move. A focused per-environment number tells you more about your model choice than a slow, expensive aggregate.
Practical recipe
- Pick the 2–3 AgentBench environments closest to your real workload.
- Run them on your top-3 candidate models. Five runs each — agents are stochastic.
- Record cost-per-task and p95 latency alongside accuracy. The leaderboard skips both.
- Compare against a baseline you control — same harness, same hosting, same temperature — so deltas mean something.
- Re-run on a quarterly cadence; new model releases change the ranking faster than the README updates.
FAQ — AgentBench Leaderboard 2026
Related Reading
- AI agent benchmarks — SWE-bench, GAIA, TAU-bench scorecardAll five major leaderboards, side by side, with the full framework comparison.
- GAIA benchmark leaderboard 2026 — 466 questions across three levelsThe depth-test counterpart to AgentBench: hand-graded assistant tasks where careful tool chains matter more than breadth.
- Claude Agent SDK production guideHow to wire the leaderboard leader into a real deployment with tool use, MCP, and durable memory.
- AI agent hosting — Railway, Modal, RunPod, VPS comparedThe hosting environment is part of the benchmark. Pick the right tier or your numbers are fiction.
- Why AI agents fail in productionThe five failure modes that explain why your benchmark agent breaks the first week it’s live.
May 6, 2026·11 min read
Tijo runs Rapid Claw, the managed-hosting layer for production AI agents. He benchmarks every major model release against the workloads our customers actually run — not the ones in the README.