Stop the $47K Runaway Loop: Rate Limiting & Cost Guardrails for AI Agents
April 18, 2026·15 min read
Security firewalls protect you from attackers. Guardrails protect you from your own agent. This guide walks through the runtime safety mechanisms — throttling, circuit breakers, budget caps, defense-in-depth — that catch runaway loops before your CFO does.
TL;DR
AI agent rate limiting guardrails are runtime safety mechanisms that run inside the agent, not just at the HTTP edge. The four you need: token-based throttling (catch context-window blowups), request-based throttling (catch retry loops), circuit breakers (trip on repeated identical calls), and budget caps (hard stop at a dollar threshold). Configure them at three layers — agent, service, infra — so any single failure can’t burn your budget. Copy-paste configs for OpenClaw and Hermes Agent below.
Want guardrails wired up on day one?
Try Rapid Claw (5 free msgs · $29/m after)The $47K Runaway Loop
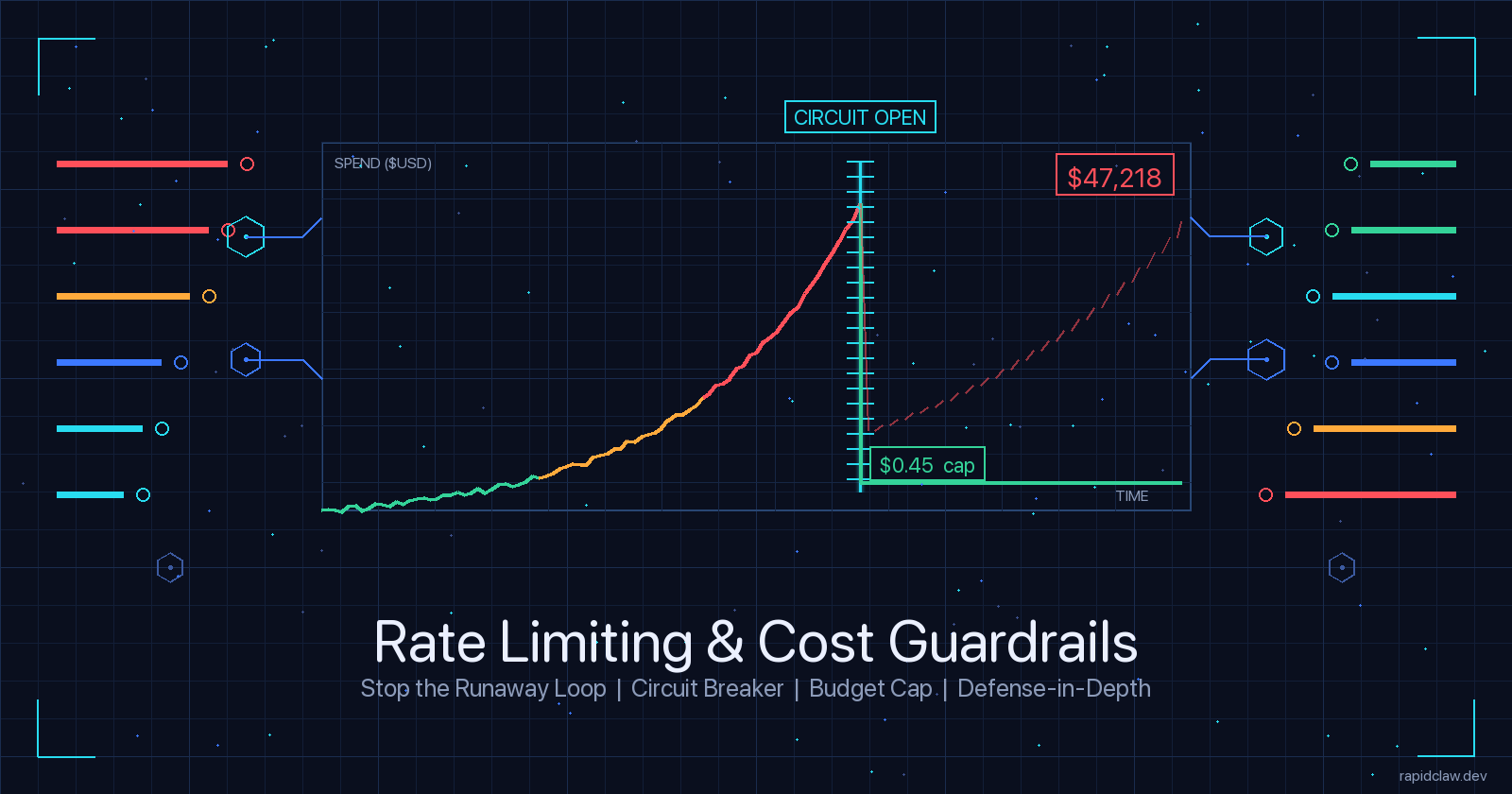
A mid-sized SaaS team pointed an agent at their support queue over a long weekend. The task was simple: triage tickets, draft replies, hand off to a human. The agent ran for 62 hours unattended. On Tuesday morning, the engineering lead opened the Anthropic dashboard to $47,218 in consumption — roughly 130× a normal week.
The postmortem was unremarkable. One specific ticket triggered a tool-call error. The agent’s prompt contained a recovery clause: “if the tool fails, retry with the same arguments.” It did. Five hundred thousand times. Each retry pulled the full ticket context back through the LLM. Each one cost roughly nine cents. No single request looked abnormal — the rate limit at the OpenAI edge was 10,000 RPM, and the agent was nowhere near that. The bill went up one nickel at a time.
There was no attacker. No prompt injection. No compromised credential. The agent did exactly what it was told — and nothing caught it. The missing piece wasn’t a firewall. It was guardrails: runtime controls that treat the agent itself as something to contain.
Firewall vs. Guardrails
A firewall answers “is this caller allowed?” — it protects against external threats. Guardrails answer “should we do this again?” — they protect against the agent’s own pathological behaviour. Both matter. This post is about the second one.
The Four Failure Modes Guardrails Catch
Before designing guardrails, it helps to know what you’re catching. In production incidents across OpenClaw and Hermes Agent deployments, four shapes show up repeatedly:
Tool retry loop
A tool returns an error. The agent retries with identical arguments. Classic cause of the $47K incident.
Context window blowup
Agent appends every tool result to context. One giant response (PDF dump, DB query) inflates every subsequent call 100×.
Plan-act oscillation
Agent plans, acts, re-plans, re-acts — swinging between two states without making progress. Visible as near-duplicate reasoning steps.
Unbounded fan-out
A sub-agent spawns N more sub-agents. Each of those spawns N more. Token cost compounds before anyone notices.
Each of these bypasses a naive HTTP rate limit. Each produces normal-looking individual requests. The only way to catch them is to measure the behaviour, not the requests.
Layer 1: Token-Based & Request-Based Throttling
Start with the cheap, boring layer: throttle both how many calls and how many tokens an agent can consume per unit time. You want both because they fail differently — a retry loop hits the request limit first, a context-blowup hits the token limit first.
Dual-throttle middleware (OpenClaw)
This middleware tracks both counters in a single Redis call using a sorted set per agent. Requests that trip either limit get a structured refusal the agent can reason about.
import time
import redis
from functools import wraps
r = redis.Redis(host="localhost", port=6379, db=0)
def dual_throttle(agent_id: str,
max_requests: int = 300,
max_tokens: int = 2_000_000,
window_sec: int = 3600):
"""
Per-agent hourly throttle — both request count AND token consumption.
Either limit tripping returns a structured refusal the LLM can reason about.
"""
def decorator(fn):
@wraps(fn)
def wrapper(*args, tokens_used: int = 0, **kwargs):
now = int(time.time())
window_start = now - window_sec
req_key = f"throttle:req:{agent_id}"
tok_key = f"throttle:tok:{agent_id}"
pipe = r.pipeline()
pipe.zremrangebyscore(req_key, 0, window_start)
pipe.zcard(req_key)
pipe.get(tok_key)
_, req_count, tok_count = pipe.execute()
tok_count = int(tok_count or 0)
if req_count >= max_requests:
return {"error": "throttled_requests",
"limit": max_requests,
"window_sec": window_sec,
"hint": "Too many tool calls this hour — slow down or ask human"}
if tok_count >= max_tokens:
return {"error": "throttled_tokens",
"limit": max_tokens,
"consumed": tok_count,
"hint": "Token budget exhausted — summarise context or stop"}
r.zadd(req_key, {f"{now}:{fn.__name__}": now})
r.expire(req_key, window_sec)
if tokens_used:
r.incrby(tok_key, tokens_used)
r.expire(tok_key, window_sec)
return fn(*args, **kwargs)
return wrapper
return decorator
@dual_throttle(agent_id="support-triage", max_requests=300, max_tokens=2_000_000)
def call_tool(name, args, tokens_used=0):
...Hermes Agent throttle config
Hermes Agent exposes throttle settings declaratively. Define separate token and request budgets per role:
throttle:
# Evaluated per-agent-instance, per-hour sliding window
support_triage:
requests_per_hour: 300
tokens_per_hour: 2_000_000
on_exceed: "refuse_with_reason" # agent sees structured error
refuse_message: |
Hourly budget reached. Summarise current progress and stop.
Resume on the next window boundary.
research_agent:
requests_per_hour: 800
tokens_per_hour: 6_000_000
on_exceed: "refuse_with_reason"
# Emergency kill-switch — applies to ALL agents
global:
requests_per_minute: 2_000 # across entire tenant
tokens_per_minute: 10_000_000
on_exceed: "halt_all" # stop-the-worldWhy return a structured error, not raise an exception?
A refusal the LLM can read is a teaching signal — well-configured agents respond by summarising progress and stopping. An exception is invisible to the model and typically triggers the exact retry loop you’re trying to prevent. Always hand the agent a reason it can reason about.
Layer 2: Circuit Breakers for Agent Loops
Throttling caps volume. Circuit breakers catch pathology — the agent isn’t over-budget, it’s stuck. You want to detect three signals: repeated identical tool calls, rising tool-call error rate, and step-count-without-progress.
Breaker pattern for agent loops
Like the classic Hystrix breaker but tuned for LLM loops. State machine: CLOSED (normal) → OPEN (halted, cooldown) → HALF_OPEN (probe). The novel bits are the triggers:
import hashlib
import time
from collections import deque
from dataclasses import dataclass, field
from enum import Enum
class State(Enum):
CLOSED = "closed"
OPEN = "open"
HALF_OPEN = "half_open"
@dataclass
class AgentCircuitBreaker:
"""
Trips when an agent exhibits pathological behaviour:
1. Same tool called with same args N times in a row
2. Error rate over last K calls exceeds threshold
3. Step count exceeds budget without a 'task_done' signal
"""
repeat_threshold: int = 5 # identical-call trigger
error_rate_window: int = 20 # look-back for error rate
error_rate_threshold: float = 0.6
step_budget: int = 80 # hard cap per task
cooldown_sec: int = 300 # how long to stay OPEN
state: State = State.CLOSED
opened_at: float = 0.0
recent: deque = field(default_factory=lambda: deque(maxlen=20))
step_count: int = 0
last_args_hash: str = ""
repeat_count: int = 0
def _fingerprint(self, tool: str, args: dict) -> str:
blob = tool + repr(sorted(args.items()))
return hashlib.sha1(blob.encode()).hexdigest()
def before_call(self, tool: str, args: dict):
# Still cooling down?
if self.state == State.OPEN:
if time.time() - self.opened_at >= self.cooldown_sec:
self.state = State.HALF_OPEN
else:
return {"tripped": True, "reason": "circuit_open",
"cooldown_remaining": int(self.cooldown_sec - (time.time() - self.opened_at))}
# Step budget
self.step_count += 1
if self.step_count > self.step_budget:
return self._trip("step_budget_exceeded")
# Repeated identical calls
fp = self._fingerprint(tool, args)
if fp == self.last_args_hash:
self.repeat_count += 1
if self.repeat_count >= self.repeat_threshold:
return self._trip("repeated_identical_calls")
else:
self.repeat_count = 0
self.last_args_hash = fp
return {"tripped": False}
def after_call(self, success: bool):
self.recent.append(1 if success else 0)
if len(self.recent) == self.recent.maxlen:
err_rate = 1 - (sum(self.recent) / len(self.recent))
if err_rate >= self.error_rate_threshold:
self._trip("error_rate_exceeded")
if self.state == State.HALF_OPEN and success:
self.state = State.CLOSED # probe worked — reset
def _trip(self, reason: str):
self.state = State.OPEN
self.opened_at = time.time()
return {"tripped": True, "reason": reason,
"cooldown_sec": self.cooldown_sec}Wiring the breaker into the agent loop
Call before_call ahead of every tool invocation and after_call with the outcome. Return the trip reason as a tool result so the LLM can course-correct.
breaker = AgentCircuitBreaker(repeat_threshold=5, step_budget=80)
def run_agent(task):
for _ in range(breaker.step_budget + 1):
action = llm.next_action(task, history)
if action.type == "finish":
return action.result
decision = breaker.before_call(action.tool, action.args)
if decision["tripped"]:
# Hand the refusal BACK to the model — not an exception.
history.append({
"role": "tool",
"name": action.tool,
"content": f"CIRCUIT OPEN: {decision['reason']}. Stop and summarise progress."
})
break
try:
result = dispatch(action.tool, action.args)
breaker.after_call(success=True)
except ToolError as e:
result = {"error": str(e)}
breaker.after_call(success=False)
history.append({"role": "tool", "name": action.tool, "content": result})Layer 3: Budget Caps & Alerting Thresholds
Throttles are time-windowed. Circuit breakers are behaviour-triggered. Budget caps are absolute dollar limits — the one thing that would have stopped the $47K incident on the first day. Three thresholds, each with a different action:
Soft (50%)
Notify on-call via Slack. No action on the agent.
Hard (80%)
Page on-call. Agent receives warning refusal for non-essential tools.
Kill (100%)
Freeze all new agent tasks for the tenant. Existing tasks refuse new tool calls.
Budget cap implementation
Track spend per agent, per task, and per tenant. The check is cheap: increment a counter after every LLM call with prompt_tokens * rate_in + completion_tokens * rate_out.
from decimal import Decimal
# Rates shown in USD per 1M tokens (April 2026 list prices — configure your own)
RATES = {
"claude-opus-4-7": {"in": Decimal("15"), "out": Decimal("75")},
"claude-sonnet-4-6": {"in": Decimal("3"), "out": Decimal("15")},
"gpt-5": {"in": Decimal("5"), "out": Decimal("20")},
}
class BudgetCap:
def __init__(self, cap_usd: Decimal, soft=Decimal("0.5"), hard=Decimal("0.8")):
self.cap = cap_usd
self.soft = cap_usd * soft
self.hard = cap_usd * hard
self.spent = Decimal("0")
self.notified = set()
def record(self, model: str, prompt_tokens: int, completion_tokens: int) -> dict:
rate = RATES[model]
cost = (Decimal(prompt_tokens) * rate["in"] +
Decimal(completion_tokens) * rate["out"]) / Decimal("1_000_000")
self.spent += cost
if self.spent >= self.cap:
return {"action": "kill", "spent": str(self.spent), "cap": str(self.cap)}
if self.spent >= self.hard and "hard" not in self.notified:
self.notified.add("hard")
return {"action": "page", "spent": str(self.spent), "level": "hard"}
if self.spent >= self.soft and "soft" not in self.notified:
self.notified.add("soft")
return {"action": "notify", "spent": str(self.spent), "level": "soft"}
return {"action": "continue", "spent": str(self.spent)}
# Enforce per-task
task_budget = BudgetCap(cap_usd=Decimal("25")) # $25/task
# Enforce per-tenant (rolling daily)
tenant_budget = BudgetCap(cap_usd=Decimal("2000")) # $2k/dayAlert rules that actually page someone
Budget breaches should route to an on-call human. Spend anomalies — even under the cap — should too. This rule set maps to PagerDuty/Slack with sensible defaults:
alerts:
- name: task_budget_soft
expr: task_spend_usd > 0.5 * task_cap_usd
severity: info
route: slack#agent-ops
- name: task_budget_hard
expr: task_spend_usd > 0.8 * task_cap_usd
severity: warning
route: slack#agent-ops,pagerduty
- name: task_budget_kill
expr: task_spend_usd >= task_cap_usd
severity: critical
route: pagerduty
action: halt_task
- name: spend_velocity_anomaly
expr: |
rate(tenant_spend_usd[5m]) >
10 * avg_over_time(rate(tenant_spend_usd[5m])[24h])
severity: critical
route: pagerduty
action: halt_all_tasks
- name: circuit_breaker_opened
expr: increase(circuit_breaker_trips_total[5m]) > 3
severity: warning
route: slack#agent-opsDefense-in-Depth: Agent, Service, Infra
The three guardrails above need to run at multiple layers. One layer is not enough — the whole point of defense-in-depth is that when (not if) one layer fails, the next catches the fall.
Agent layer — in the loop
Circuit breaker, step budget, per-tool request throttle. Lives inside the agent process, closest to the behaviour. Fastest to react, but trusts the agent code itself to be correct.
Catches: tool retry loops, plan-act oscillation, step explosions.
Service layer — at the API proxy
LLM gateway (LiteLLM, Helicone, Portkey, or a homemade proxy) between the agent and provider. Enforces per-agent token throttle, per-task budget cap, and spend tracking. Survives even a buggy agent that ignores its own breaker.
Catches: context-window blowups, unbounded fan-out, agents that swallow their own throttle errors.
Infra layer — at the billing edge
Provider-side spend limits (Anthropic usage limits, OpenAI monthly caps) plus your own daily-spend kill-switch wired to a monitoring job. The last line of defense. Catches everything, but only once real money has moved.
Catches: everything else, including bugs in your other guardrails.
Reference config: the three-layer stack
A minimal production config pinning all three layers together. Adjust the numbers for your workload, but keep the shape.
# Layer 1 — AGENT (inside the process)
agent:
circuit_breaker:
repeat_threshold: 5
error_rate_threshold: 0.6
step_budget_per_task: 80
cooldown_sec: 300
tool_throttle:
web_search: { rpm: 20, per: "agent_id" }
database_read: { rpm: 50, per: "agent_id" }
send_email: { rpm: 5, per: "agent_id" }
# Layer 2 — SERVICE (LLM gateway / proxy)
service:
llm_gateway:
per_agent_tokens_per_hour: 2_000_000
per_task_usd_cap: 25
per_tenant_tokens_per_minute: 10_000_000
max_prompt_tokens: 180_000 # catch context blowup
on_exceed: "refuse_with_reason"
# Layer 3 — INFRA (kill-switches)
infra:
daily_tenant_usd_cap: 2000
provider_limits:
anthropic_monthly_usd: 5000
openai_monthly_usd: 5000
kill_switch:
spend_velocity_multiplier: 10 # vs 24h baseline
window: "5m"
action: "halt_all_tasks"Would this have caught the $47K loop?
Yes, three times over. The circuit breaker trips at step 5 of identical retries (cost: ~$0.45). Failing that, the per-task $25 cap halts at call ~280 (cost: $25). Failing that, the daily tenant cap of $2,000 fires ~40× faster than the actual incident did. The whole point of defense-in-depth is you don’t need every layer to work — you need at least one to work.
What to Monitor After You Ship
Guardrails rot. Thresholds that were right at launch are wrong six months later as traffic shifts. The metrics you want on a dashboard, checked weekly:
- •Trip rate by reason — if repeated_identical_calls is 10× other reasons, your agent prompts need work, not your threshold.
- •P99 task cost in USD — if the long tail is climbing, your task budget cap is loose.
- •Refusal-to-completion ratio — refusals that lead to clean task completions mean the guardrails are teaching. Refusals followed by abandonment mean the limits are too tight.
- •Spend velocity (USD/minute) — the single most actionable metric. Any 10× jump vs. a rolling baseline should page.
- •Step-count distribution per task — a bimodal distribution (lots of short tasks + a fat tail) is the signature of pathological behaviour that the breaker is catching. A unimodal tail means your budget is bang-on.
If you’re already instrumenting this, pair it with full agent observability so every trip and refusal has a trace you can drill into. Without traces, you’ll know you caught something but not what to fix.
The managed alternative
Wiring three layers of guardrails yourself is a week or two of work, then an ongoing tuning loop. Rapid Claw ships all three layers pre-configured: per-agent circuit breakers, an LLM gateway with per-task USD caps, and tenant-level kill-switches. Defaults are tuned against real incident data — including the one above.
Frequently Asked Questions
Ship with guardrails, not without
Rapid Claw deploys OpenClaw and Hermes Agent with circuit breakers, budget caps, and LLM-gateway throttling pre-wired. No more Sunday-night surprise invoices.
Deploy with guardrails includedRelated reading
Security-side companion: rate limits, API keys, network isolation
AI Agent Token CostsHow a single agent hits $100K/year — and what drives it
AI Agent ObservabilityTraces, metrics, and logs so trips actually tell you something
Why AI Agents Fail in ProductionFailure modes that chew through budgets, and how to design around them
The AI Agent Marketplace, MappedMarketplace agents are the strongest case for hard rate limits and budget caps