RAG Architecture for AI Agents: Vectors, Chunking & Agentic Patterns (2026)

April 30, 2026·20 min read
Agentic RAG is RAG where the agent itself decides when to retrieve, what to query, and whether to re-retrieve — turning a fixed pipeline into a tool the agent calls deliberately. By 2026 it is the production default for AI systems that answer complex questions, navigate messy data, or take real action on behalf of users. Five canonical patterns cover almost every use case: iterative retrieval, query decomposition, hypothesis-driven retrieval, cross-corpus triangulation, and evidence-weighted synthesis. This guide covers the full architecture (retrieval, augmentation, generation), vector databases, chunking, embeddings, the agentic RAG patterns, and how to deploy RAG-powered agents on Rapid Claw.
Quick Answer (Agentic RAG, 2026)
- Definition: Agentic RAG = the agent decides when to retrieve, what to query, whether to re-retrieve. Retrieval is a tool, not a pipeline stage.
- 5 canonical patterns: iterative retrieval, query decomposition, hypothesis-driven retrieval (HyDE), cross-corpus triangulation, evidence-weighted synthesis.
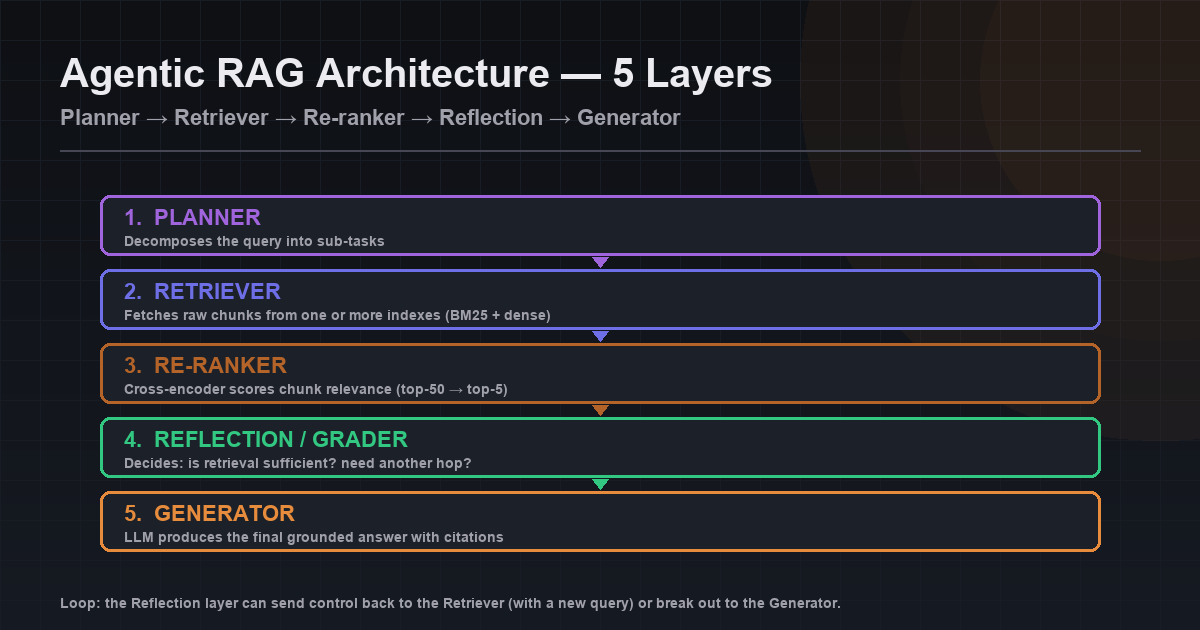
- Architecture (5 layers): planner → retriever → re-ranker → reflection/grader → generator.
- When to use: hybrid RAG is the production baseline for most queries; agentic RAG is the escalation path for multi-hop, ambiguous, or planning-heavy queries.
- Vanilla vs agentic: vanilla = one retrieval, fixed K, one answer. Agentic = retrieve zero/one/many times, decide which corpus, grade results, stop when satisfied.
TL;DR
RAG architecture for AI agents is three stages: retrieval (find relevant context from a vector DB), augmentation (inject it into the prompt), generation (LLM produces a grounded answer). In 2026, the action has shifted to agentic RAG — where the agent itself decides when to retrieve, what to query, and whether to re-retrieve. Multi-hop RAG chains queries; self-reflective RAG critiques its own retrieval; HyDE embeds a hypothetical answer; CRAG falls back to web search on weak chunks. This guide covers the components, the chunking and embedding tradeoffs, the agentic patterns, and how to deploy RAG-powered agents on Rapid Claw.
Want a managed vector store wired into your agent?
Deploy on Rapid ClawWhat RAG Is — And Why Agents Need It
Retrieval-Augmented Generation was introduced by Lewis et al. in 2020 as a way to combine a parametric model (the LLM) with a non-parametric knowledge source (a retrievable corpus). Six years later, the core idea hasn’t changed — but the implementations have exploded in sophistication. For AI agents specifically, RAG solves four problems the base model can’t:
Freshness
An LLM’s knowledge is frozen at training time. RAG lets the agent read documents you indexed this morning.
Groundedness
Retrieved snippets give the model concrete material to cite, sharply reducing hallucination on factual queries.
Scale
A 10M-document corpus doesn’t fit in any context window. RAG narrows it to the handful of chunks the agent actually needs.
Specialization
Your internal wiki, your product docs, your support history — none of it is in the base model. RAG makes it available without fine-tuning.
A common objection in 2026: why not just use a 2M-token context window and stuff everything in? Because context is expensive, latency-sensitive, and lossy. The well-documented lost-in-the-middle effect shows that models recall the start and end of a long context far better than the middle. RAG sidesteps that entirely by only sending what matters.
If you’re already thinking about how agents hold information across turns, this pairs naturally with AI agent memory & state management. RAG is the long-term knowledge layer; the memory system handles working state across a task.
The Three Stages: Retrieval, Augmentation, Generation
Every RAG system — no matter how fancy — is still some variant of these three stages. Understand them in isolation before you layer on agentic behavior.
1. Retrieval
The agent (or a fixed pipeline) turns a query into a search over your knowledge base. In vector-based RAG, that means embedding the query into the same vector space as your documents and pulling the top-K nearest neighbors. In modern production systems this is almost always hybrid: a dense vector search for semantic similarity, plus a sparse keyword search (BM25) for exact-match terms, combined with a re-ranker on top.
2. Augmentation
Retrieved chunks are assembled into the LLM prompt — usually as a system or user message block with instructions like “Answer using only the context below. If the answer isn’t in the context, say so.” The augmentation step is deceptively important: how you format, deduplicate, order, and cap the context directly shapes answer quality.
3. Generation
The LLM produces an answer grounded in the augmented context. Production RAG systems also ask for structured output (JSON, citations with source IDs, confidence scores) so downstream code can reason about the response rather than just displaying it.
from openai import OpenAI
from qdrant_client import QdrantClient
client = OpenAI()
vdb = QdrantClient(host="localhost")
def rag_answer(question: str, k: int = 5) -> dict:
# 1. Retrieval — embed the query and pull top-K chunks
q_emb = client.embeddings.create(
model="text-embedding-3-small",
input=question,
).data[0].embedding
hits = vdb.search(
collection_name="docs",
query_vector=q_emb,
limit=k,
with_payload=True,
)
# 2. Augmentation — format chunks into a prompt
context = "\n\n".join(
f"[{h.payload['source']}] {h.payload['text']}" for h in hits
)
# 3. Generation — ask the LLM to answer ONLY from context
response = client.chat.completions.create(
model="gpt-4.1-mini",
messages=[
{"role": "system", "content": (
"Answer the user's question using only the context below. "
"Cite sources with [source]. If the answer is not in the "
"context, say 'I don't know based on the provided documents.'"
)},
{"role": "user", "content": f"Context:\n{context}\n\nQuestion: {question}"},
],
)
return {
"answer": response.choices[0].message.content,
"sources": [h.payload["source"] for h in hits],
}That’s vanilla RAG in ~30 lines. It works. It’s also where most production systems start — and where most of them stall, because the default behavior (one retrieval, fixed K, no reasoning about relevance) breaks as soon as questions get complex.
Vector Databases: The Storage Layer
The vector database is where your embedded chunks live. It needs to answer one question fast, at scale: “which of these N vectors are closest to this query vector?” In 2026 the field has settled into a handful of serious options.
| Vector DB | Best For | Trade-off |
|---|---|---|
| Qdrant | Self-hosted, high performance, rich filtering | Ops burden if you self-host at scale |
| Pinecone | Fully managed, minimal ops | Cost at scale, vendor lock-in |
| Weaviate | Hybrid search, GraphQL, managed or self | Heavier footprint than Qdrant |
| Milvus | Billion-scale, GPU-accelerated indexes | Complex cluster setup |
| pgvector | You already run Postgres; <10M vectors | Slower than purpose-built DBs above ~10M |
| LanceDB | Embedded, on-disk, zero ops for prototypes | Not built for multi-node production |
Underneath all of them is some variant of HNSW (Hierarchical Navigable Small World graphs) or IVF indexes. You don’t need to implement either — but you do need to understand the two knobs that govern recall vs. latency: ef_construction / ef_search for HNSW, and nprobe for IVF. Higher values = better recall, slower queries. Tune on your own queries, not synthetic benchmarks.
Metadata filtering is not optional
Every serious RAG system uses filtered search: tenant_id, document_type, updated_after, language. Without filtering, retrieval gets noisy fast — and in multi-tenant deployments, it’s also a security hole. Pick a vector DB whose filtering is pre-filter (applied before the ANN search), not post-filter, or recall on filtered queries will collapse.
Chunking Strategies: Where Most RAG Systems Fail
Chunking — how you split documents before embedding — is the single most under-respected knob in RAG. Chunk too small, and the agent retrieves tokens that lack surrounding context. Chunk too large, and the embedding becomes an average of many concepts, losing the specificity that made it retrievable in the first place.
The chunking decision tree
- Prose (docs, articles, policies): recursive character splitting, 512–1024 tokens, 10–20% overlap. The
RecursiveCharacterTextSplitterdefault is a reasonable starting point. - Structured content (code, tables, JSON): chunk along semantic boundaries — function, class, row group, JSON object. Never split mid-function.
- FAQs / Q&A pairs: one chunk per pair. Do not merge unrelated questions.
- Long, hierarchical docs: parent-document retrieval. Embed small chunks for recall precision, but return the larger parent chunk to the LLM for context.
- Tables: convert to markdown or CSV rows, keep headers with each chunk, and store the table schema in metadata.
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Solid default for prose content
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120,
separators=["\n## ", "\n### ", "\n\n", "\n", ". ", " ", ""],
length_function=len,
)
def chunk_document(doc: dict) -> list[dict]:
"""Chunk a document and attach metadata to each chunk."""
raw_chunks = splitter.split_text(doc["content"])
return [
{
"text": chunk,
"source": doc["source"],
"doc_id": doc["id"],
"chunk_idx": i,
"title": doc.get("title"),
"updated_at": doc.get("updated_at"),
# Parent-document retrieval: keep a pointer to the larger parent
"parent_chunk_id": f"{doc['id']}::parent::{i // 4}",
}
for i, chunk in enumerate(raw_chunks)
]Always evaluate chunking on your own queries
Build a small eval set of 30–100 real questions with known correct answers. Then try three chunk sizes (say 400, 800, 1500 tokens) and measure recall@5 for each. This 2-hour experiment routinely beats weeks of architectural hand-wringing. The same principle applies to evaluating agents in general — see AI agent testing in production for the broader loop.
Embedding Models in 2026
Embeddings are how you turn text into vectors. Your retrieval is only as good as your embedding model. A few options that are genuinely good in 2026:
- OpenAI
text-embedding-3-large: strong English performance, supports dimension reduction down to 256 without major recall loss — great for cost control. - Cohere
embed-v4: multilingual and multimodal, often wins on non-English corpora. - Voyage
voyage-3: domain-specific variants (code, finance, law) that beat generic models on specialist content. - BGE-M3 / E5-Mistral (open-source): self-host-able, competitive with proprietary models on MTEB, and they run on a single GPU.
- Re-rankers (Cohere Rerank, BGE reranker): strictly better than raw vector similarity — retrieve top-50 with the embedding model, re-rank to top-5 with a cross-encoder.
The re-ranker pattern is important enough to call out. Raw vector similarity is a noisy proxy for relevance. Re-rankers look at the query and the chunk together and score relevance directly. The compute cost is tiny compared to the LLM call that follows, and the quality improvement is routinely measurable.
Agentic RAG: When the Agent Decides
Vanilla RAG is a fixed pipeline. The agent gets a query, the pipeline retrieves 5 chunks, the LLM answers. That’s fine for a FAQ bot. It’s not enough for agents that need to reason, decompose, and act.

Agentic RAG gives the agent agency over retrieval. Retrieval becomes a tool the agent can call — not a pipeline stage that runs unconditionally. Concretely, the agent decides:
- Whether to retrieve at all. “What’s 2+2?” doesn’t need a vector search. Simple chitchat doesn’t either. Unnecessary retrieval adds latency and pollutes the context.
- What query to issue. The user’s literal question is often a bad search query. The agent can rewrite it, expand it with synonyms, or split it into sub-queries.
- Which index to search. If you have multiple corpora (docs, tickets, code, Slack), let the agent pick based on the question.
- Whether the results are good enough. If the retrieved chunks don’t cover the question, re-retrieve with a different query rather than hallucinating.
- When to stop. Once it has the answer, stop retrieving. Retrieval loops are a real failure mode.
# Agentic RAG: expose retrieval as a tool the agent calls deliberately.
RETRIEVAL_TOOL = {
"type": "function",
"function": {
"name": "search_knowledge_base",
"description": (
"Search the company knowledge base. Use this when the user's "
"question requires factual information from internal docs, "
"tickets, or policies. Do NOT call for generic knowledge, "
"greetings, or math."
),
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "A focused search query. Rewrite the user's "
"question into a keyword-rich query if helpful.",
},
"index": {
"type": "string",
"enum": ["docs", "tickets", "code", "slack"],
"description": "Which corpus to search.",
},
"k": {
"type": "integer",
"default": 5,
"description": "How many chunks to retrieve.",
},
},
"required": ["query", "index"],
},
},
}
def handle_retrieval_tool(args: dict) -> str:
hits = vdb.search(
collection_name=args["index"],
query_vector=embed(args["query"]),
limit=args.get("k", 5),
with_payload=True,
)
return "\n\n".join(
f"[{h.payload['source']}] {h.payload['text']}" for h in hits
)The entire RAG pipeline is now one tool the agent can call zero, one, or many times per task. That small reframing unlocks everything below.
Agentic RAG Architecture: The 5 Canonical Patterns
Five patterns cover almost every production agentic RAG use case in 2026. Most real systems compose two or three. Naming them explicitly is what stops your agent loop from becoming a mystery.
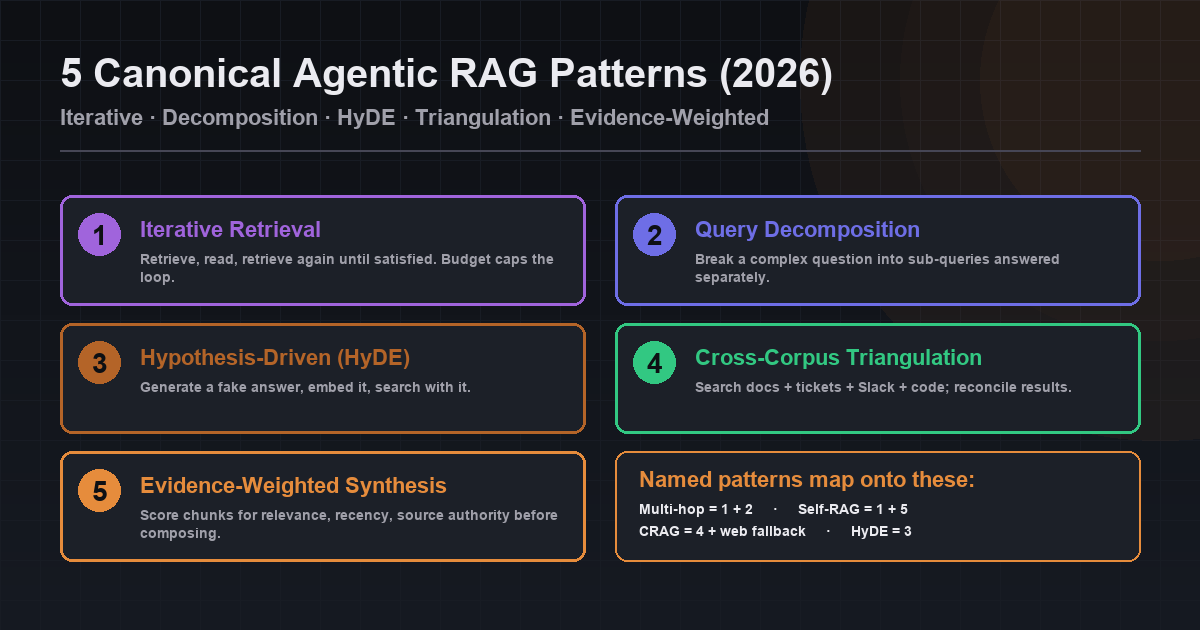
Iterative retrieval
Retrieve, read, retrieve again until satisfied. The agent keeps a budget (max hops) and stops as soon as it has enough. The simplest agentic pattern and the one that handles the largest share of "vanilla RAG missed it" cases.
Query decomposition
Break a complex multi-part question into sub-queries the agent can answer separately, then merge the answers. "Compare our Q3 churn to industry average and explain the gap" decomposes into three queries against three different corpora.
Hypothesis-driven retrieval (HyDE)
Generate a hypothetical answer to the question first, embed that, and use it as the search query. A fake answer is often a better query than the literal question because it is phrased like the documents you are searching.
Cross-corpus triangulation
Search multiple indexes (docs, tickets, code, Slack) for the same question and reconcile the results. Useful when no single corpus contains the full answer — the agent sees fragments across sources and stitches them.
Evidence-weighted synthesis
Score retrieved chunks for relevance, recency, and source authority before composing the answer. The agent weighs a 2024 official policy doc differently from a 2022 Slack thread when both could answer the question.
The named research patterns map onto these primitives. Multi-hop RAG is iterative retrieval with query decomposition. Self-reflective RAG (Self-RAG) is iterative retrieval with evidence-weighted synthesis. Corrective RAG (CRAG) is cross-corpus triangulation with a web-search fallback. Treat the five patterns as the vocabulary; the named papers are concrete combinations.
Hybrid RAG is the default; agentic is the escalation
Most production systems should not default to agentic RAG. Classic hybrid RAG (BM25 + dense vectors + cross-encoder re-ranker) handles the majority of queries faster and cheaper. Agentic RAG is the escalation path for queries that need planning, multi-hop reasoning, or tool use beyond retrieval. Route at the top: cheap classifier decides "vanilla path" vs "agentic path" before either pipeline runs.
Advanced Patterns: Multi-Hop & Self-Reflective RAG
Multi-Hop RAG
Some questions require more than one lookup. “Who wrote the onboarding doc that our current CTO approved last quarter?” needs three hops: (1) who’s the current CTO, (2) what did they approve last quarter, (3) who authored the doc. Single-shot retrieval can’t handle this — the query never matches all three facts simultaneously.
Multi-hop RAG turns retrieval into a loop. The agent retrieves, reads the results, identifies what’s still missing, and retrieves again with a new query. Each hop is a tool call. The loop terminates when the agent believes it has enough, or when a max-hops budget is exhausted.
MAX_HOPS = 4
def multi_hop_answer(question: str) -> dict:
messages = [
{"role": "system", "content": (
"You are a research agent. Use search_knowledge_base as many "
"times as needed to answer the user's question. Think step by "
"step: identify what you need, search for it, evaluate the "
"results, and search again if anything is missing. Stop as "
"soon as you have enough."
)},
{"role": "user", "content": question},
]
for hop in range(MAX_HOPS):
response = client.chat.completions.create(
model="gpt-4.1",
messages=messages,
tools=[RETRIEVAL_TOOL],
)
msg = response.choices[0].message
if not msg.tool_calls:
return {"answer": msg.content, "hops": hop}
messages.append(msg)
for tc in msg.tool_calls:
result = handle_retrieval_tool(json.loads(tc.function.arguments))
messages.append({
"role": "tool",
"tool_call_id": tc.id,
"content": result,
})
# Budget exceeded — force a final answer from what was gathered
messages.append({"role": "user", "content": (
"You've used your retrieval budget. Answer now with what you have, "
"or explicitly state what's still unknown."
)})
final = client.chat.completions.create(model="gpt-4.1", messages=messages)
return {"answer": final.choices[0].message.content, "hops": MAX_HOPS}Self-Reflective RAG
Self-reflective RAG — introduced in the Self-RAG paper and now a standard pattern — adds an explicit grading step after retrieval. Before generating the final answer, the model evaluates whether the retrieved chunks are actually relevant and sufficient. If not, it re-retrieves with a different query, or decides the knowledge base doesn’t contain the answer.
def grade_relevance(question: str, chunks: list[str]) -> dict:
"""Ask a cheap model to grade whether chunks actually answer the question."""
prompt = (
f"Question: {question}\n\n"
f"Retrieved chunks:\n"
+ "\n---\n".join(chunks)
+ "\n\nReturn JSON: {\"relevant\": bool, \"sufficient\": bool, \"missing\": str}"
)
response = client.chat.completions.create(
model="gpt-4.1-mini", # Grader can be cheaper than the generator
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
)
return json.loads(response.choices[0].message.content)
def self_reflective_rag(question: str) -> dict:
query = question
for attempt in range(3):
chunks = retrieve(query, k=5)
grade = grade_relevance(question, chunks)
if grade["relevant"] and grade["sufficient"]:
return generate_answer(question, chunks)
# Re-query based on what was missing
query = rewrite_query(question, missing=grade["missing"])
return {"answer": "I couldn't find enough information in the knowledge base.",
"attempts": 3}Two other patterns worth naming in passing:
- HyDE (Hypothetical Document Embeddings): ask the LLM to generate a hypothetical answer to the question, then embed that and use it as the search query. A fake answer is often a better query than the literal question because it’s phrased like the documents you’re searching.
- Corrective RAG (CRAG): classify each retrieved chunk as correct, ambiguous, or incorrect. On ambiguous or incorrect, fall back to web search before generating. Useful when your corpus has known gaps.
All of these patterns compose. Real production systems often chain multi-hop retrieval, re-ranking, and self-reflective grading into a single agent loop. The observability story matters a lot here — a six-step RAG pipeline is hard to debug without traces. If that’s where you’re headed, see AI agent observability and debugging AI agents step-by-step.
RAG Failure Modes (And How to Catch Them)
Retrieval recall is silently bad
Your agent gives plausible answers that are subtly wrong because the right chunk was never retrieved. Fix: build an eval set, measure recall@K, tune chunking and the re-ranker.
Context overflow
You retrieve 20 chunks, they blow past the model’s useful context, and quality drops. Fix: smaller K, tighter re-ranking, or parent-document retrieval with bounded context.
Stale embeddings
Documents change, embeddings don’t. The agent confidently cites outdated policy. Fix: re-embed on update, store a content hash, and include updated_at in metadata for filtering.
Tenant bleed
Multi-tenant deployments forget to filter by tenant_id, and customer A sees customer B’s data. Fix: enforce tenant filtering in the retrieval tool, not the application layer.
Retrieval loops
Agentic RAG without a hop budget keeps retrieving forever. Fix: hard cap on tool calls per task, token budget per task, and structured logging for loop detection.
Most of these map to broader production issues covered in why AI agents fail in production. RAG doesn’t exempt you from the normal rules of running agents; it just adds a new surface to monitor.
Deploying RAG-Powered Agents on Rapid Claw
You can absolutely build all of the above yourself — self-host Qdrant, wire up an embedding pipeline, glue it into your agent framework, set up metrics, handle re-embedding on content updates. The shortcut, if you’d rather spend your time on the agent logic, is to run it on a platform that handles the infrastructure.
Rapid Claw deploys OpenClaw and Hermes Agent with a managed retrieval layer attached. Concretely that means:
- Managed vector store: a tenant-isolated Qdrant instance per deployment. No provisioning, no HNSW tuning.
- Embedding pipeline: upload documents via the dashboard or API; they’re chunked, embedded, and indexed. Re-embeds on content change.
- Retrieval tool pre-wired: the agent already has a
search_knowledge_basetool exposed. Agentic RAG works out of the box. - Hybrid search + re-ranker: BM25 + dense retrieval + cross-encoder re-ranking, configurable per index.
- Observability: every retrieval call is traced, graded, and logged — so when an answer is wrong, you can see exactly which chunks the agent saw.
- Cost controls: per-agent retrieval budgets and token caps, covered in smart routing for token costs.
The build-vs-buy call
For a prototype, roll your own — pgvector and an embedding call is a weekend. For production with SLAs, tenant isolation, re-embedding on content updates, and observability across the pipeline, you’re looking at weeks of engineering plus ongoing maintenance. Rapid Claw exists for the second case. Build the agent, bring your content, skip the plumbing.
Frequently Asked Questions
Ship a RAG-powered agent without running a vector DB
Rapid Claw runs OpenClaw and Hermes Agent with managed retrieval attached — hybrid search, re-ranking, agentic RAG patterns, and tracing included. Upload your docs, wire up the tool, ship in an afternoon.
Deploy with retrieval includedRelated reading
Context, long-term persistence, and vector stores for agents
AI Agent Observability GuideTrace every retrieval, grade every answer, debug with proof
Why AI Agents Fail in ProductionRetrieval loops, stale context, and the other usual suspects
AI Agent Framework Comparison (2026)Hermes, CrewAI, LangGraph, AutoGen, OpenClaw compared