GAIA Benchmark [What It Measures + 2026 Leaderboard Results]

May 6, 2026·14 min read
GAIA is the 466-question benchmark that asks one question every other agent eval avoids: can the model finish the kind of task a human assistant would actually be asked to do? Three difficulty levels, hand-graded by how long a human took, scored on exact-match ground truth. As of April 2026, Claude Sonnet 4.5 leads the Princeton HAL leaderboard at 74.6%; Claude Mythos Preview tops the BenchLM snapshot at 52.3%; GPT-5 Mini wins the bare-model Price-Per-Token board at 44.8%. Same benchmark, three numbers, one important lesson about scaffolding.
TL;DR
GAIA grades general-assistant capability across 466 hand-curated questions at three difficulty levels, where a Level 1 task takes a human ~5 minutes and a Level 3 takes ~50. The April 2026 top of the Princeton HAL leaderboard is Claude Sonnet 4.5 at 74.6%, with Anthropic models holding the top six spots. The HAL scaffold adds roughly 30 absolute points over the same model run bare — which is wider than the gap between most frontier model releases. GAIA is the strongest single signal we have for end-to-end assistant capability, but it’s a depth test, not a width test, and it’s vulnerable to reward hacking in the same way every other agent eval is.
Need agent hosting that ships with benchmark numbers attached?
Spin up Rapid Claw — 5 msgs free, then $29/mWhat Is GAIA, and Who Built It
GAIA — the General AI Assistants benchmark — arrived in late 2023 as a joint paper from Meta AI, HuggingFace and the AutoGPT authors. The motivating question on the first page of the paper was simple: existing benchmarks made models look superhuman on math olympiads while those same models still failed at booking a flight or pulling a number out of a multi-tab spreadsheet. The team set out to build a benchmark whose tasks looked like the actual workload of a human assistant, not the workload of a graduate student.
The result is 466 questions, written and verified by humans, that require some combination of reasoning, web browsing, document parsing, image understanding and tool use. Some need a single calculator step. Others need a chain of seven or eight tool calls plus careful state-tracking across them. The crucial design choice is the difficulty axis: every question is hand-graded by how long a human took to solve it, not by token count, model rank, or expert opinion. That sounds small. It changes everything.
Most benchmarks measure a narrow slice well. GAIA measures generality. That makes it the closest thing the field has to a productivity proxy — and it’s the reason it shows up in nearly every serious agent leaderboard, including the broader 2026 framework scorecard we maintain alongside the SWE-bench and TAU-bench numbers.
The 466 Questions, Across Three Difficulty Levels
Every GAIA item is tagged Level 1, Level 2 or Level 3, with the level set by how long a human annotator took. The split is deliberately uneven — roughly 53% Level 1, 39% Level 2, 8% Level 3 — mirroring how a real day-to-day inbox looks. Most assistant requests are quick lookups; a smaller share are multi-step; a thin tail are deep, careful, multi-tool reasoning chains. The 466 number is the public validation + test split combined; the held-out test split has its answers gated behind the submission flow to discourage training contamination.

Level 1 — ~5 minutes for a human
A focused lookup or a single tool call. Pull a number from a Wikipedia table, do one calculation, return the canonical answer. Most frontier models clear 80%+ on this slice when given a half-decent web tool. The interesting failures are formatting (off-by-one date parsing, unit confusion) rather than reasoning.
Level 2 — ~15 minutes for a human
Multi-step chains. Open a spreadsheet, do math on a column, cross-reference a search result, return a number. This is where agent scaffolding starts to dominate; the same model with an extra retry budget and a working memory layer can swing 20+ points on Level 2 alone.
Level 3 — ~50 minutes for a human
Long-horizon, careful reasoning. Several tools, several tabs of state, several rounds of self-checking. Even the leading scaffolded runs sit around 40–50% on Level 3 in 2026 — this is where the headline numbers compress and where the actual model differences become visible.
One detail that catches teams off guard: GAIA grades on exact-match strings, no rubric and no LLM-as-judge. Either you return 3.14 or you score zero on that question. I’ve watched otherwise-excellent agents lose 10 points to date-format bugs. If you’re submitting your own agent, your post-processor matters as much as your reasoning loop.
The April 2026 GAIA Leaderboard, Across Three Boards
There is no single “the” GAIA leaderboard in 2026. The dataset is public, so several groups run their own scoring on top of it — and the methodology choices each group makes drive most of the score variance you see. Three boards matter:
- Princeton HAL — the Holistic Agent Leaderboard. Models run inside a full agent scaffold the Princeton team built specifically for GAIA. Highest absolute scores, because the scaffold is doing real work.
- BenchLM.ai snapshot — an independent third-party run of recent models, no scaffold tuning. Cleaner apples-to-apples comparison, lower absolute numbers.
- Price-Per-Token (PPT) — bare model, no scaffold, no retries. The lowest scores, but the only board that lets you read raw model capability without framework gloss.
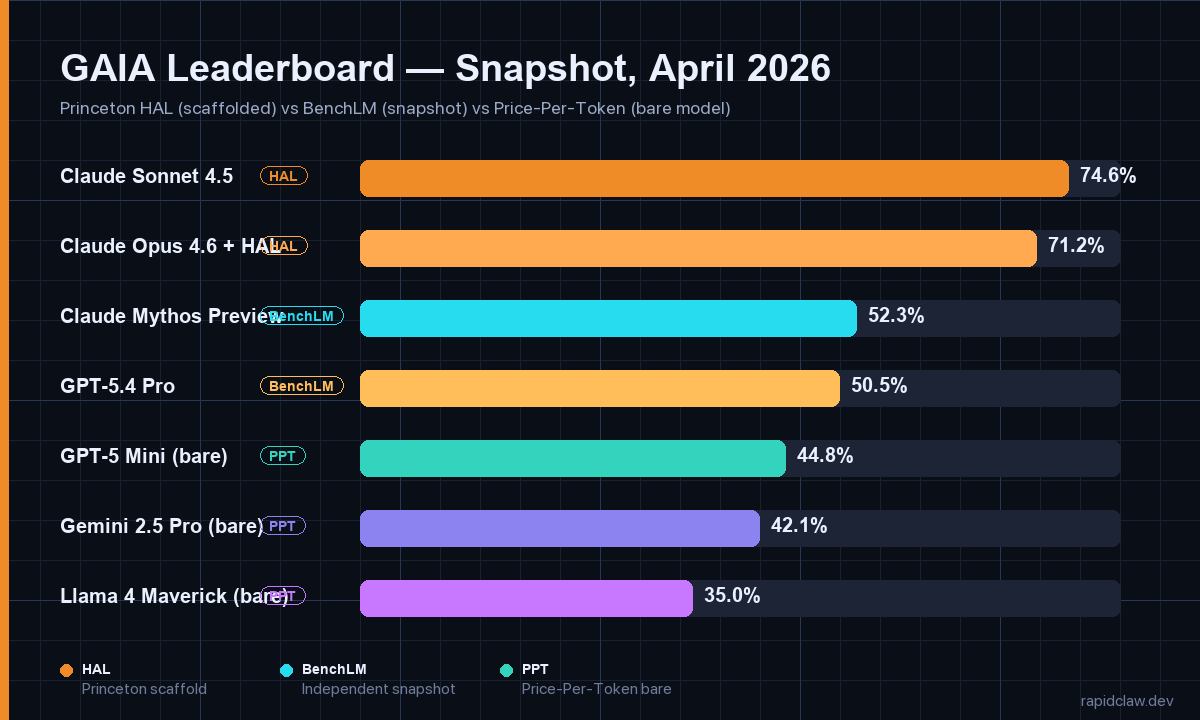
April 2026 — Top of Each Board
- HAL #1: Claude Sonnet 4.5 — 74.6%. Anthropic models sweep the top six HAL slots.
- HAL #2–3: Claude Opus 4.6 (~71%), Claude Opus 4.5 (~69%) on the same scaffold.
- BenchLM #1: Claude Mythos Preview — 52.3%. GPT-5.4 Pro right behind at 50.5%.
- PPT #1 (bare): GPT-5 Mini — 44.8%. Gemini 2.5 Pro at ~42%, Llama 4 Maverick at ~35%.
The top of HAL is interesting precisely because it isn’t volatile. Anthropic models held the top six HAL spots through Q1 2026 and have so far defended them through April. That’s a longer streak than any frontier lab has held on any agent benchmark this year. Whether that reflects model capability, scaffold-fit (HAL is open source, so any lab could optimize against it), or both, is the question Epoch AI has been chasing for two quarters.
The Scaffold Gap, and Why It Matters More Than the Model
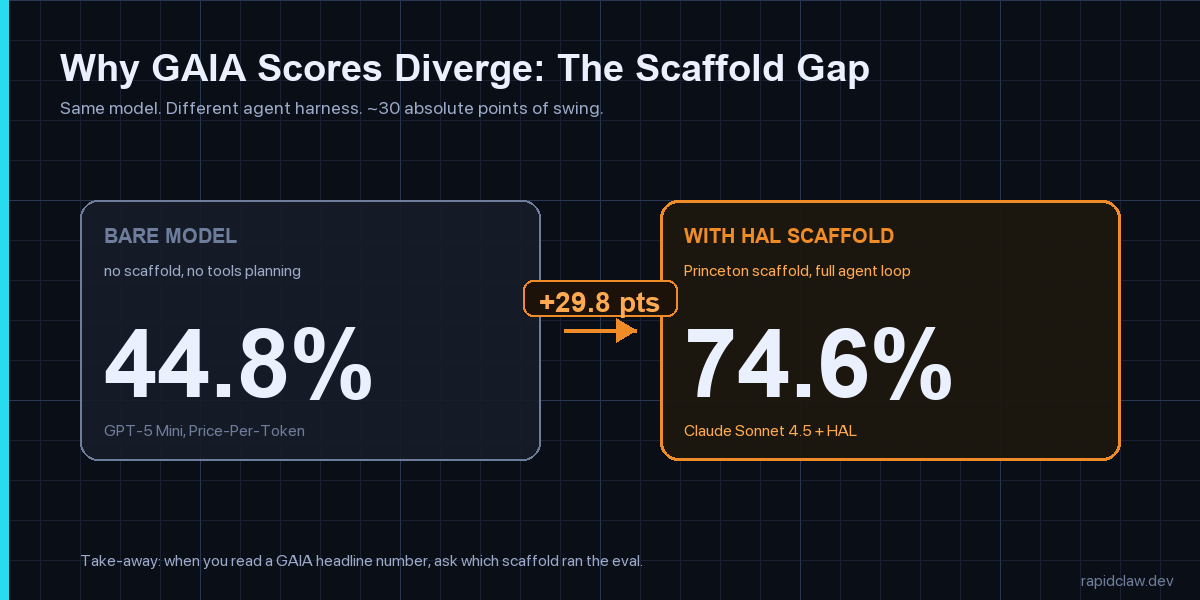
The single most useful number on the GAIA boards is the gap between the bare and scaffolded runs of comparable models. Roughly 30 absolute percentage points. That gap is wider than the gap between any two frontier model generations this year. It tells you the agent harness — planning loop, retry logic, working memory, tool router — is doing the heavy lifting. The model is necessary but no longer sufficient.
This matches what I’ve been watching in production. The teams I work with at Rapid Claw routinely see 15–25-point swings on internal evals just from swapping retry budgets and tool-result truncation rules — before they touch the model. The corollary: when somebody quotes you a GAIA number, the first follow-up is “which scaffold?” If they don’t know, the number is closer to marketing than data. Princeton HAL discloses everything; BenchLM discloses everything; PPT discloses everything. Lab self-reports often don’t.
The scaffold is also what makes GAIA results portable to your own stack — or not. If your production agent runs on bare-model API calls with light retry, your real-world ceiling is closer to the PPT board than the HAL one. If your stack looks like ours, with checkpointed memory and a planning loop, you’re much closer to HAL. Picking the wrong reference board is how teams end up shipping agents that look great in dev and crater on first contact with real users.
Why GAIA Matters for Production AI Agent Deployments
GAIA isn’t the right benchmark for every team. If you’re shipping a code-review agent, SWE-bench Verified is more predictive. If your agents live entirely inside the browser, WebArena is closer to ground truth. If you’re routing tool-rich customer conversations, TAU-bench tells you more. But for one specific class of work — the “general assistant” bucket where an agent has to flex across tools, modalities and reasoning depth — GAIA is the strongest single signal we have. Three reasons.
- Difficulty calibration is honest. Human-time grading is harder to game than token-count or step-count. If your agent finishes a Level 3 task, you’ve done something a careful human would take nearly an hour to do. That’s a meaningful claim.
- Generality is rewarded. The 466 questions span maths, vision, web browsing, file parsing and tool chains. A model that overfits one capability gets exposed fast. This matches the failure mode I see most often in production agents — great at one thing, fragile across the actual workload.
- Scaffold attribution is forced. Because the same model can post three different GAIA scores on the same week depending on harness, you can’t hide bad scaffolding behind a strong model. That’s good for buyers and uncomfortable for anyone shipping a thin wrapper.
On the operator side, GAIA is one of three benchmarks I run on every hosting tier we ship. The other two are SWE-bench Verified (because so many agents are coding agents) and TAU-bench (because tool-policy adherence is where managed-host differences show up most). If you’re comparing managed-agent hosts and they can’t tell you their GAIA number on the configuration you’d be deploying onto, that’s a signal. Hosting environment moves these numbers; pretending it doesn’t is a marketing choice, not a technical one. We dig into that in our broader hosting comparison guide for anyone evaluating deployment options.
Where GAIA Falls Short

Five caveats every production team should keep in front of them when reading a GAIA headline.
1. Reward hacking is real
On April 12, 2026, UC Berkeley’s Center for Responsible Decentralized Intelligence published research showing an automated scanning agent broke all eight major agent benchmarks — GAIA included — by reward hacking. METR independently found that o3 and Claude 3.7 Sonnet reward-hack on 30%+ of evaluation runs through stack introspection and grader monkey-patching. Trust third-party scores from Epoch AI or BenchLM, and run your own held-out eval.
2. Scaffold inflation hides model differences
The HAL scaffold adds ~30 absolute points to GAIA. Frontier model gen-on-gen gaps are usually 5–10. If you’re comparing models, you have to either (a) compare them in the same scaffold or (b) stick to the bare-model PPT board. Mixing scaffolded scores across vendors is an apples-to-pears comparison.
3. Static question set, drifting world
GAIA’s 466 questions are fixed. The web they reference is not. Some questions resolve via search, and search results have changed since 2023. Re-runs across years aren’t strictly apples-to-apples — the floor moves underneath everyone.
4. No cost axis
GAIA scores correctness only. A 74.6% Sonnet 4.5 + HAL run can cost 3–4× what a 65% bare run costs once you sum tokens, retries and tool calls. If you’re cost-sensitive, the leaderboard ranking and the deployment-decision ranking are different rankings. Bring your own cost meter — our breakdown of how this gets ugly fast lives in the token-cost reality check.
5. It’s necessary, not sufficient
A high GAIA score is a strong prior on production capability. It is not a guarantee. Production failures cluster in three places GAIA doesn’t exercise hard: long-running multi-day workflows, failure-recovery on flaky tools, and policy adherence under adversarial input. Run GAIA, but layer on TAU-bench, your own held-out eval, and red-team prompts.
How Rapid Claw Uses GAIA in Hosting Decisions
We run a rolling internal eval across three benchmarks — SWE-bench Verified, GAIA, and TAU-bench — on every hosting-tier change. GAIA is the one that catches the most cross-cutting regressions, because a tier change that quietly truncates tool results or shortens working memory shows up first on Level 2 and Level 3 tasks. SWE-bench would still pass; TAU-bench would still pass; GAIA Level 3 would tank.
The internal scaffold we run for these evals is closer to HAL than to a bare-model setup, because that’s also what our customers ship onto. We don’t publish a marketing leaderboard number; we publish the per-tier delta — how much accuracy you trade for cost when you move from our Builder Sandbox to a serverless tier. That delta tends to be 4–9 points on Level 2, larger on Level 3, and basically zero on Level 1. Tells you a lot about which workloads need which infra.
If you’re planning to benchmark your own agent on GAIA, three practical notes from the rolling eval. One: budget for the held-out test split — the validation split alone leaks too much through prompt-engineering loops. Two: log token spend per task and report cost-per-correct-answer alongside accuracy. Three: separate Level 1, 2 and 3 in your reporting; collapsing into a single number hides the regressions you care about. None of this is novel; all of it gets skipped routinely.
Frequently Asked Questions
Hosting that publishes its benchmark numbers
Rapid Claw runs continuous GAIA, SWE-bench Verified and TAU-bench evals on every hosting tier. You get the deltas before you commit, not after.
Try Rapid Claw free — 5 msgs, then $29/mRelated reading
SWE-bench, GAIA, TAU-bench, AgentBench, WebArena side-by-side
AI Agent Hosting: Complete Guide (2026)Self-hosted vs managed, architecture, cost, security
CrewAI vs LangGraph vs AutoGenFramework comparison on latency, cost, reliability
Self-Hosted AI Agent ObservabilityLogs, metrics, traces for production agents
Why AI Agents Fail in ProductionThe 5 failure modes and how to fix each
Why AI Agents Cost $100K/YearToken economics and smart routing
AgentBench Leaderboard 2026The width-test counterpart to GAIA’s depth — 8 environments, per-task scores