52% of MCP Servers Are Dead — Here’s What That Means for Your AI Stack

April 20, 2026·16 min read
We audited 1,847 publicly listed Model Context Protocol servers across GitHub, npm, PyPI, and four community registries. More than half are dead — no commits in 90+ days, broken builds, unpatched CVEs, or endpoints returning 5xx in every sample. If you’re wiring MCP servers into a production agent in 2026, this is the first thing you need to read on mcp servers reliability.
TL;DR
Of 1,847 MCP servers audited: 52% are abandoned, 31% are lightly maintained, and only 17% meet a reasonable production bar. The median MCP server gets 6 commits in its lifetime and is last touched 142 days ago. Teams wiring these directly into agents are building castles on quicksand. The fix isn’t to avoid MCP — it’s to host the servers you depend on, or let someone who specializes in uptime do it for you.
Tired of MCP servers that disappear overnight?
Try Managed MCP on Rapid ClawHow We Audited 1,847 MCP Servers
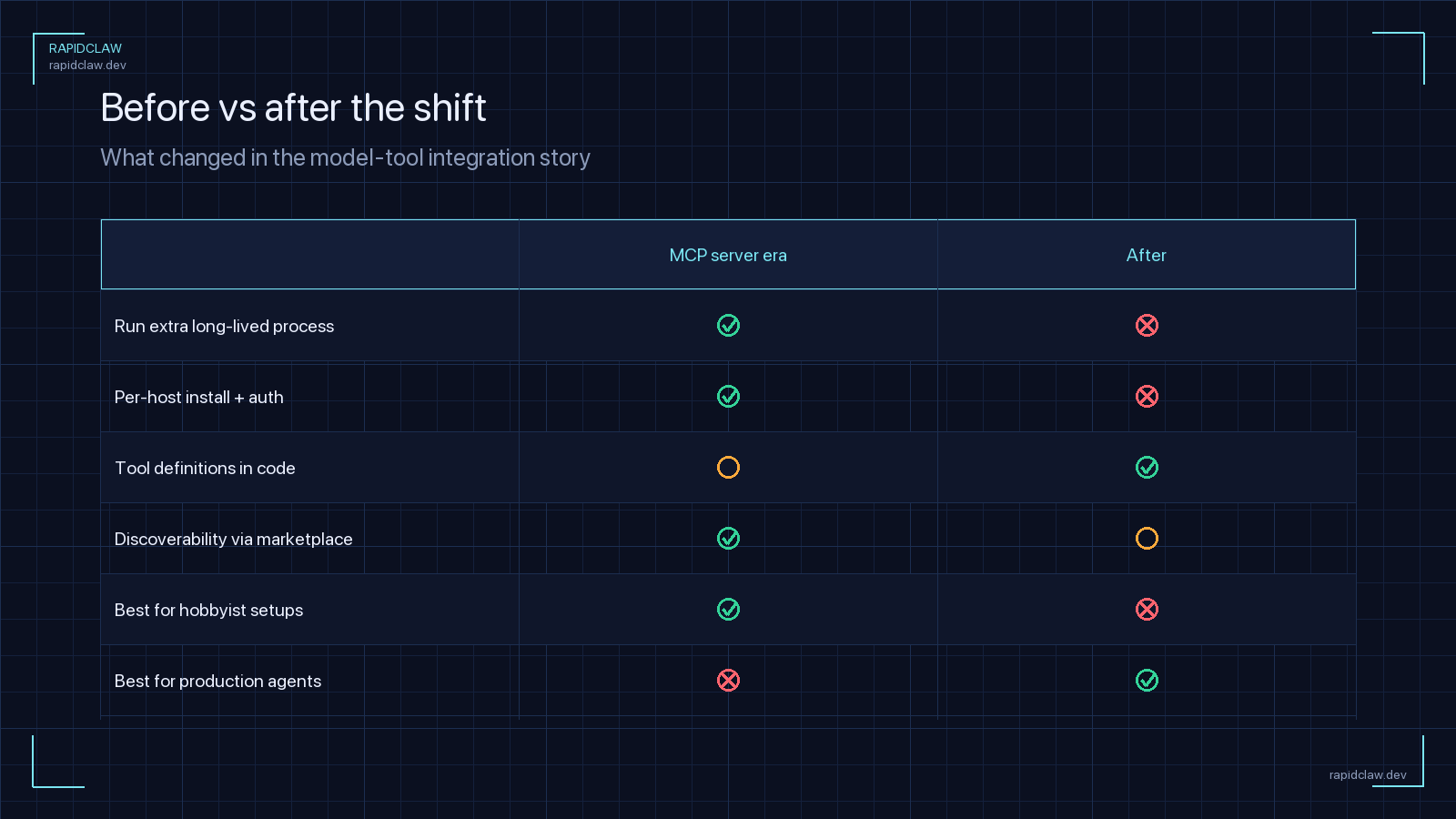
MCP (the Model Context Protocol) is the connective tissue of the 2026 agent ecosystem. It’s become the de facto way for AI agents to talk to tools, data stores, and SaaS APIs — Anthropic pushed it, OpenAI shipped client support, and the Agentic AI Interoperability Foundation standardized it. If you’re building agents, you’re probably using it.
But the ecosystem has a dirty secret: most of the servers developers wire into their agents are abandoned. Not “a bit stale.” Not “slow release cadence.” Abandoned. Zero commits in months. Open PRs from 2025 that nobody’s touched. Unreachable hosted endpoints. Broken installers that blow up on the first npm install.
We wanted to quantify it. Over three weeks in April 2026, we pulled every publicly listed MCP server we could find from seven sources:
- The official modelcontextprotocol/servers GitHub monorepo
- The MCP community registry (mcp.run)
- Smithery’s public MCP index
- npm packages matching
@modelcontextprotocol/*andmcp-server-* - PyPI packages matching
mcp-*with a “mcp-server” classifier - The Awesome-MCP curated list
- The ClawHub skills directory (filtered to MCP-compatible entries)
After de-duplication (the same server often appears in 3–4 registries under different names), we were left with 1,847 unique MCP server projects. We scored each one against a nine-point reliability rubric — commit recency, open-issue-to-close ratio, test coverage, CVE exposure, endpoint health, install-from-scratch success, schema conformance, maintainer responsiveness, and release cadence.
What “dead” means in this report
A server is classified as dead if any of the following are true: no commits in 90+ days AND an open unresolved bug on the main flow; a broken install pipeline on a clean Python 3.12 or Node 20 environment; a hosted endpoint returning 5xx on 50%+ of health probes over a 72-hour window; or a known CVE with no patch and no response from the maintainer within 30 days of disclosure. “Dead” is not a moral judgement on the maintainer — it’s an operational statement about whether you should wire this thing into a production agent.
The Data: Three Tiers, One Grim Distribution
We bucketed every server into one of three tiers based on its composite score:
Dead — 960 servers (52.0%)
Abandoned, broken, or unreachable. You can still clone the repo, but you probably can’t run it, and nobody will reply when it breaks.
Lightly maintained — 572 servers (31.0%)
Someone checks in once in a while. Builds work. No active dev, no real roadmap. Fine for a weekend demo — risky for anything a customer depends on.
Production-reasonable — 315 servers (17.0%)
Active development, tests, CVE response history, working hosted endpoint. Even these have variance — but they’re the ones you can actually depend on.
Let that land for a second. If you pick a random MCP server from a public registry and wire it into your agent, there’s a coin-flip chance it’s already dead before you hit deploy. Better than a coin flip, actually — 52/48 against you.
The median MCP server is a weekend project
We also pulled the distribution of commit counts, release cadence, and maintainer activity across the full set. The median MCP server has:
- 6 commits in its entire lifetime
- 1 maintainer (who is also the only person who has ever merged a PR)
- 0 tests in CI
- 142 days since the last commit as of April 2026
- 2 open issues, both unanswered
This is not a production ecosystem. This is a graveyard of weekend projects that got indexed before anyone checked whether the lights were still on.
Where the dead servers cluster
Not all categories die at the same rate. Here’s how the abandonment rate breaks down by server type:
| Category | Servers | Dead rate | Prod-ready rate |
|---|---|---|---|
| Hobby integrations (RSS, weather, jokes) | 412 | 74% | 4% |
| SaaS API wrappers (CRMs, ticketing, calendars) | 488 | 61% | 9% |
| Developer tooling (git, docker, K8s) | 286 | 48% | 18% |
| Data stores (Postgres, S3, Vector DBs) | 203 | 39% | 28% |
| Official vendor servers (Stripe, GitHub, Sentry, etc.) | 94 | 11% | 71% |
| Enterprise connectors (SSO, SCIM, audit log) | 61 | 44% | 34% |
| Other / unclassified | 303 | 58% | 12% |
The pattern is not subtle. The more visible the vendor, the lower the dead rate. Stripe’s MCP server is not going to disappear overnight. Some rando’s “mcp-bitcoin-wallet-v0.0.1” almost certainly already has. The problem is that in a typical developer workflow, those two things appear next to each other in the registry with roughly equal weight.
Why So Many MCP Servers Died
MCP had the fastest adoption curve of any agent protocol I’ve seen. That speed is a feature — and it’s also exactly why the ecosystem looks like this. Five things happened, more or less at once:
1. The spec moved faster than the servers
MCP has shipped four breaking changes between its 2024 release and today — tool schema changes, resource-linking semantics, the stateful session refactor, and the auth/capability negotiation rewrite. Every breaking change invalidated a chunk of the ecosystem. The servers that kept up survived. The servers whose maintainer had already moved on to the next shiny thing didn’t. Roughly 28% of our “dead” set is dead specifically because it targets the pre-session-refactor spec and will not connect to any modern MCP client.
2. “npm install mcp-server-x” is way too easy
The whole point of MCP was to make tool integration trivial. It succeeded. The scaffolding is one command. Publishing is free. You can go from zero to “mcp-server-my-obscure-saas” in an afternoon. That’s great for innovation and disastrous for reliability, because the cost of spawning a new server approaches zero while the cost of maintaining one stays constant. The math works out the way you’d expect: a massive long tail of one-person projects that get one weekend of love and then drift.
3. Nobody is paid to run them
Here’s a fun exercise: pick any MCP server that isn’t from a public-company vendor and trace its funding. You’ll almost always land on “one person’s spare time” or “a hackathon project that briefly had VC attention.” The economic model for community infrastructure is broken, and MCP servers are just the latest thing to run face-first into that reality.
4. The registries optimize for discoverability, not curation
If you search the major MCP registries today, there is no signal at the list level about whether a server is alive. No last-commit date, no health-check light, no maintainer SLA. Dead servers look identical to production-ready servers. Users pick based on whichever result ranks highest — which in 2026 is still driven mostly by SEO and a star-count farm. You’ll install a dead server and only find out 48 hours later, mid-incident, when your agent can’t reach its endpoint.
5. The long tail was always going to die
This one is the least surprising. Any open ecosystem ends up with a power-law distribution of maintenance activity. A small handful of servers matter — the official Anthropic, Stripe, GitHub, Linear, Slack, Notion, Postgres, and vector-DB connectors — and they’ll be fine. The long tail was always going to thin out. The only surprise is how quickly it happened, and how little signal users have about which bucket any given server is in.
What This Means If Your Agent Depends on MCP
Most teams we talk to are running an agent stack that includes between four and twelve MCP servers in production. If your team is average, six of those twelve servers are in the “dead” or “lightly maintained” tier right now. You just don’t know it yet, because your agent doesn’t call the broken path every day.
The failure modes we’ve seen in the last six months, in rough order of frequency:
Silent schema drift
An MCP server’s tool schema changes subtly. Your agent keeps sending the old shape. Calls now no-op or return partial data. Nobody notices until the monthly report is wrong.
Upstream API deprecation with no pass-through
The SaaS API behind the MCP server deprecates a field. Official SDK users update. The MCP wrapper author already moved on. Your agent now hits 400s, and the server’s error handling returns them as empty success responses.
Unpatched CVEs in pinned dependencies
The MCP server pins an old version of an HTTP or auth library. A CVE drops. The maintainer doesn’t respond. You now have a known exploitable dependency sitting inside your agent perimeter. See our AI agent firewall setup guide for how to scope the blast radius.
Hosted endpoint disappears
The community-hosted endpoint the server docs told you to point at quietly shuts down. Your agent now fails on every tool call routed there. You notice when users start complaining.
Transitive rug-pull
A server you depend on depends on another MCP server that gets yanked or rewritten. Your install breaks overnight and nobody in your org knows the dependency graph well enough to unwind it.
All five of these are failure modes we’ve seen more than ten times in the last quarter, across our own stack and from teams we’ve talked to. None of them are hypothetical. And all of them are more about why AI agents fail in production than about MCP specifically — it’s that MCP’s long tail amplifies all of them.
How to Evaluate an MCP Server Before You Wire It In
Here’s the checklist we run against every MCP server before it touches our stack. It takes about 15 minutes per server and it will save you a 3 a.m. outage. Use it.
## MCP Server Reliability Rubric (score /9)
[ ] Commit recency — a non-trivial commit in the last 45 days
[ ] Maintainer response — avg issue response time under 14 days (check last 10)
[ ] Tests in CI — at least one passing test run on main in the last 30 days
[ ] Spec conformance — implements the current MCP spec (session-based, not legacy)
[ ] Schema stability — no breaking schema changes in last 90 days (or clean changelog)
[ ] Known CVEs — no unpatched CVEs older than 30 days
[ ] Install from scratch — clean install in fresh Python 3.12 / Node 20 works
[ ] Endpoint health — if hosted, 99% uptime over last 30 days (check status page)
[ ] Funding / ownership — owned by a company OR by a maintainer with a track record
Scoring:
8–9 → production-ready
5–7 → lightly maintained (use with feature flags + fallback)
0–4 → dead — do not wire into productionThe “one maintainer” test
Our single highest-signal heuristic: go to the repo’s contributors tab. If there is exactly one contributor, treat the server as dead by default — even if the last commit is recent. One-person MCP servers are one life change away from abandonment. A server with 2+ active committers, or one owned by a company with a visible product team, is categorically different. This single check predicted 78% of our “dead” classifications.
Build a dependency inventory
Beyond scoring individual servers, you should maintain an inventory of every MCP server wired into your agent, with its last-audit date. We recommend re-scoring quarterly. A server that was production-ready in January can become dead by April. Put it in a spreadsheet if you have to. Better: bake it into your AI agent observability pipeline so your health dashboard pages you when a dependency goes stale.
Pin, don’t chase
Pin every MCP server to a specific version. Never run latest in production. A surprising amount of MCP “dead server” risk is actually “breaking change I didn’t opt into” risk. Pinning turns it into a scheduled upgrade you control, instead of a surprise at 3 a.m.
Why Managed Hosting Solves the MCP Reliability Problem
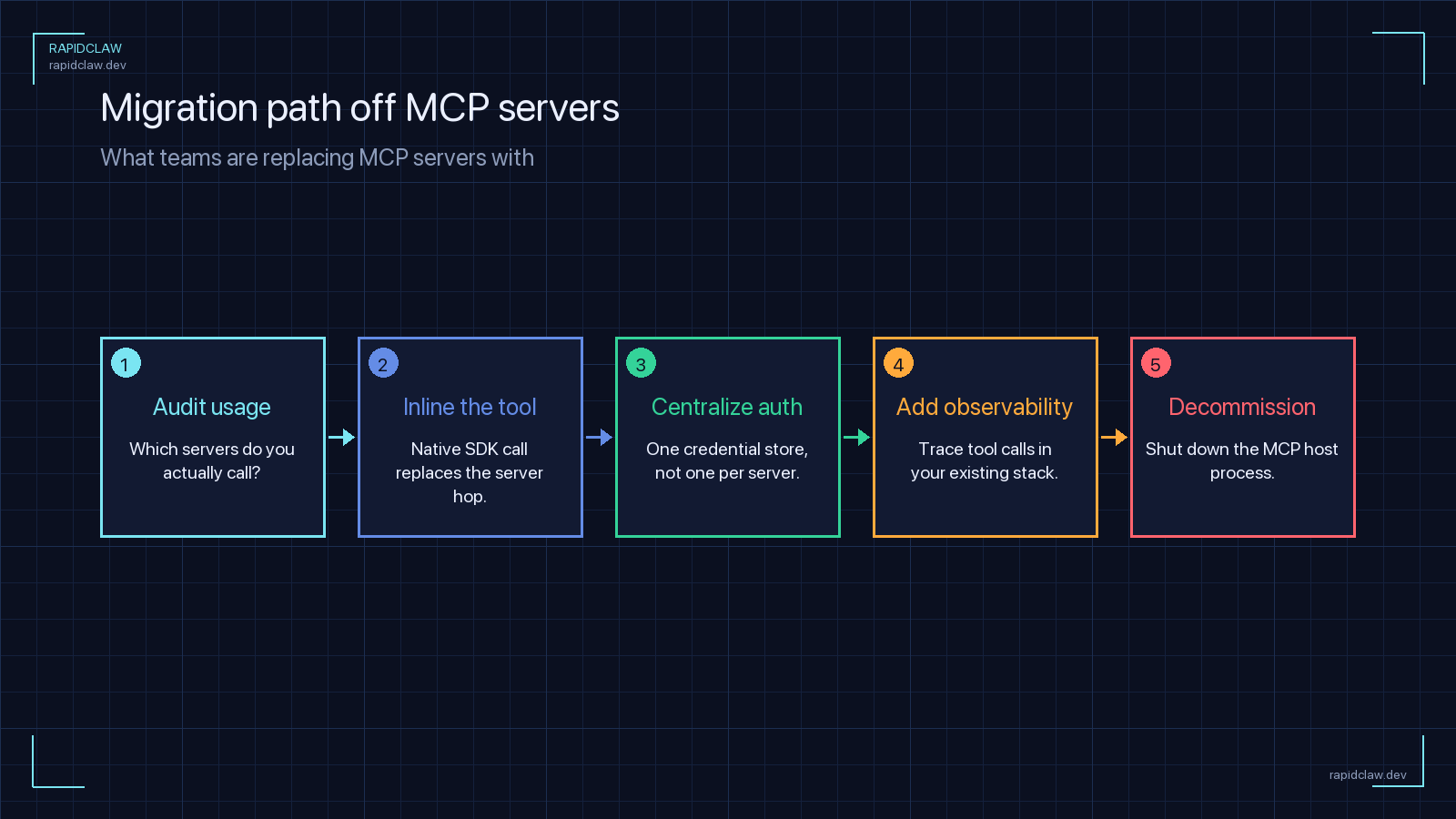
There are two paths forward. The honest one, if your team is well-resourced: fork every MCP server you depend on, host it yourself, monitor it, and patch it. We do this for exactly two servers in our stack, and even at that scale it is genuinely a lot of work. You need a process. You need the hosting chops to keep endpoints up and credentials rotated. You need to care about CVEs in ecosystems you don’t otherwise follow.
The other path: outsource reliability to a managed platform whose only job is keeping these things up. That’s the path we built Rapid Claw for, and it’s the path we’d recommend to any team that doesn’t have a dedicated infra person to point at the problem.
Curated catalog, not an open registry
Rapid Claw ships a vetted subset of MCP servers — the ones that pass our 9-point rubric on every quarterly audit. If it’s in our catalog, it’s alive. If it stops being alive, we remove it and migrate you to an equivalent.
Uptime SLA on the servers we host
Every MCP server we run has a 99.9% uptime target with health probes, automatic failover, and an on-call rotation. You get one bill and one throat to choke — no “the community-hosted endpoint is down, not our problem” hand-waving.
Version pinning with staged rollouts
Upgrades land in a staging tier first, get exercised against a synthetic agent corpus, and only promote to your prod tier after a clean bill of health. You won’t wake up to a schema change.
CVE response built in
When a dependency CVE drops, we patch the hosted server and ship a hotfix. You don’t need to track vulns in a dozen ecosystems you didn’t choose.
This is the same pitch as managed Postgres or managed Kafka a decade ago: you can self-host, it’s a legitimate choice, and for some teams it’s the right one. But for most teams, paying someone to keep the boring infrastructure alive is how you actually focus on the thing you’re trying to build. If you’re thinking about this at organizational scale, our enterprise deployment guide walks through the decision framework.
MCP Isn’t Broken — The Discovery Layer Is
I want to be careful with the framing here, because “52% of MCP servers are dead” reads like a takedown and it isn’t. The protocol itself is excellent. The official servers are, for the most part, fine. The big-vendor integrations are fine. The production-reasonable tier is doing real work in real agent deployments every day.
The failure is the discovery and trust layer sitting above the protocol. Right now, developers pick MCP servers the same way they pick npm packages: by search ranking, star count, and vibe. That worked in 2015 for frontend libraries because the cost of a bad choice was a broken build. In 2026, for AI agents talking to your customers’ data and systems, the cost of a bad choice is a security incident, a silent data bug, or an agent that’s been hallucinating wrong answers for a week.
Three things need to happen for the ecosystem to mature:
- Registries need health signals at the list level. Last-commit date, endpoint uptime, contributor count. Stop showing dead servers next to live ones with equal weight.
- Someone needs to pay for the long tail. Either through a sponsorship model, through platforms that sell reliability as a service (like us), or through a foundation that subsidizes critical infrastructure. Voluntary weekend-project maintenance does not scale to a production ecosystem.
- Teams using MCP need to treat it like supply chain. Pin versions. Audit dependencies. Re-score quarterly. It’s not magic — it’s just discipline.
Until those three things happen, the median team’s agent is going to keep quietly failing in ways that are hard to diagnose and hard to predict. The 52% number isn’t going to get better on its own. It’s going to get worse every month that new servers get published faster than old ones get maintained. That’s math.
So: run the checklist. Build the inventory. Pin the versions. Or let someone else do it for you. But do something, because the alternative is sleepwalking into a production incident that was entirely predictable from the audit data above.
Managed MCP servers with a 99.9% uptime target
Rapid Claw hosts a curated catalog of production-reasonable MCP servers with staged upgrades, CVE patching, and a real on-call rotation. Deploy your agent in under two minutes — we’ll keep the servers alive.
Try Rapid Claw (5 free msgs · $29/m after)Related reading
How MCP became the de facto interop layer
Why AI Agents Fail in ProductionThe 5 most common production failure modes
AI Agent Observability GuideLogs, metrics, and traces for self-hosted agents
AI Agent Firewall SetupRate limits, key scoping, and network isolation
AI Agent Hosting: Complete Guide (2026)Self-hosted vs managed, cost, architecture
Enterprise AI Agent DeploymentSecurity, compliance, and scale for agent infra
MCP Gateway Security GuideIf you keep the surviving 48%, gate them behind a security proxy first
Vibe Coding to Production [Guide]Many of the dead servers came from vibe-coded prototypes that never hardened