Low-Code AI Agent Platforms Compared (2026): n8n vs Flowise vs Dify — and When to Go Code-First

April 20, 2026·18 min read
Low-code agent builders are having a moment. n8n, Flowise, and Dify each claim to let non-engineers ship production AI agents from a canvas. This guide cuts through the marketing — honest feature-by-feature comparison, pricing, where each platform breaks down at scale, and when to skip low-code entirely for a code-first framework.
TL;DR
Dify wins for chat-first RAG apps and beginners. n8n wins for ops-heavy automations where AI is one step in a larger workflow. Flowise wins for LangChain-style prototyping on a visual canvas. All three break down when you need long-running multi-agent state, sub-second latency, or CI-grade tests — that’s when code-first frameworks (LangGraph, CrewAI, OpenClaw, Hermes Agent) earn their keep. Rapid Claw deploys any of them.
Need to deploy any of these stacks without the DevOps?
Try Rapid Claw — 5 msgs free, then $29/mThe Rise of Low-Code Agent Builders
Two years ago the only way to ship an AI agent was Python, a fistful of prompt templates, and a shaky while true loop around an LLM call. By 2026 that’s changed. A class of low-code platforms — n8n, Flowise, and Dify lead the pack — lets a product manager, ops lead, or founder drag nodes onto a canvas, connect them to OpenAI or Anthropic, and deploy a working agent in an afternoon.
The pitch is seductive for good reasons. LLM apps are mostly plumbing: prompt templates, retrieval, tool calls, a bit of conditional branching, a chat UI. Visual builders compress that plumbing into thirty minutes. A recent CB Insights count put the combined GitHub star base of n8n, Flowise, and Dify north of 300,000 — most of that growth in the past 18 months. Enterprise buyers are paying attention too: Gartner’s 2026 low-code/no-code Magic Quadrant added a dedicated “AI-augmented development” axis for the first time.
But the pitch hides tradeoffs. Visual runtimes abstract away the parts of an agent that matter most in production: context management, parallel tool calls, retry logic, token accounting, evaluation, versioning. For hobby projects that doesn’t matter. For a customer-support agent handling 10,000 tickets a day, it’s the difference between a $200 and a $20,000 monthly bill. The rest of this guide is about telling those two situations apart.
Meet the Three Contenders
n8n — the workflow-first builder
Started in 2019 as an open-source Zapier alternative. 65k+ GitHub stars. Originally about connecting SaaS tools — Gmail to Sheets, HubSpot to Slack — but in 2024 shipped a first-class AI Agent node built on LangChain, plus nodes for vector stores, embeddings, memory, and tool calling.
Sweet spot: ops and internal automations where the LLM is one step in a longer workflow. “When a Stripe subscription cancels, summarise the support history with GPT-4, post it to Slack, and open a retention ticket in Linear” is a perfect n8n job.
Flowise — LangChain on a canvas
Launched late 2023 as a visual builder for LangChain and LlamaIndex. 35k+ stars. The node graph maps almost one-to-one onto LangChain primitives: chains, agents, retrievers, memory, tools. Flowise 2.0 (Q4 2025) added first-class multi-agent orchestration and a visual LangGraph editor.
Sweet spot: developers who like LangChain’s abstractions but want a faster prototype loop. It’s also the easiest of the three to “eject” from — export the flow as JSON, translate back to Python, and you have a production LangChain app.
Dify — the LLMOps-first app builder
The newest and fastest-growing of the three. 55k+ stars, most added in the last 12 months. Dify is less of a general workflow tool and more of an opinionated stack: chat assistants, text generators, agent apps, and workflow apps, all sitting on a shared dataset-aware RAG layer with evaluation and observability baked in.
Sweet spot: “I want to build a ChatGPT for our docs” or “I need a customer-facing AI app, not an internal workflow.” The best built-in RAG of the three, the best eval tooling, and the most polished end-user chat UI.
Feature-by-Feature Comparison

Here’s the head-to-head across the dimensions that actually matter when you’re choosing a platform. I’ve spent real time in all three — these are the honest edges I ran into, not brochure copy.
| Dimension | n8n | Flowise | Dify |
|---|---|---|---|
| Core metaphor | Linear workflows + AI node | LangChain DAG on a canvas | Opinionated LLM app stack |
| Learning curve | Low (Zapier-like) | Medium (LangChain concepts) | Very low for chat apps |
| Built-in RAG | Basic (vector store nodes) | Good (full LangChain retrievers) | Excellent (dataset-native) |
| Multi-agent orchestration | Weak (no native pattern) | Strong (v2.0 LangGraph) | Moderate (Agent nodes) |
| Tool/integration count | 400+ connectors | ~100 via LangChain | ~80 native + HTTP |
| Built-in evaluation | None | Minimal | Strong (datasets + scoring) |
| Observability | Execution logs only | LangSmith hook | Native tracing + metrics |
| Self-host | Docker, K8s | Docker, K8s | Docker, K8s, Helm |
| License | Fair-code (Sustainable Use) | Apache 2.0 | Apache-like (Dify OSL) |
| Ejection path | JSON export; not portable | Flow → LangChain code | REST API; locked to runtime |
Pricing (2026)
All three are free to self-host. The comparison that matters is the hosted cloud tier, where pricing models differ in ways that catch teams off guard.
| Platform | Free | Starter | Metered on |
|---|---|---|---|
| n8n Cloud | No | $24/mo | Workflow executions |
| Flowise Cloud | Yes (limited) | $35/mo | Predictions + nodes |
| Dify Cloud | Yes (200 msgs) | $59/mo | Messages + docs indexed |
The subtle trap: in all three cloud tiers, LLM token costs are on top of the platform bill. An n8n workflow that fires 10,000 times a month and calls GPT-4 on each run can easily cost $500–$2,000 in OpenAI fees while you’re sitting on the $24 plan. For high-volume agents the platform fee is a rounding error next to your model bill — which is exactly why token cost control becomes the real scaling question.
Want code-level control without the ops?
Rapid Claw runs OpenClaw on managed infrastructure. You get the full code-level agent and we handle hosting, patching, and routing. $29/mo to start.
When Low-Code Is the Right Call
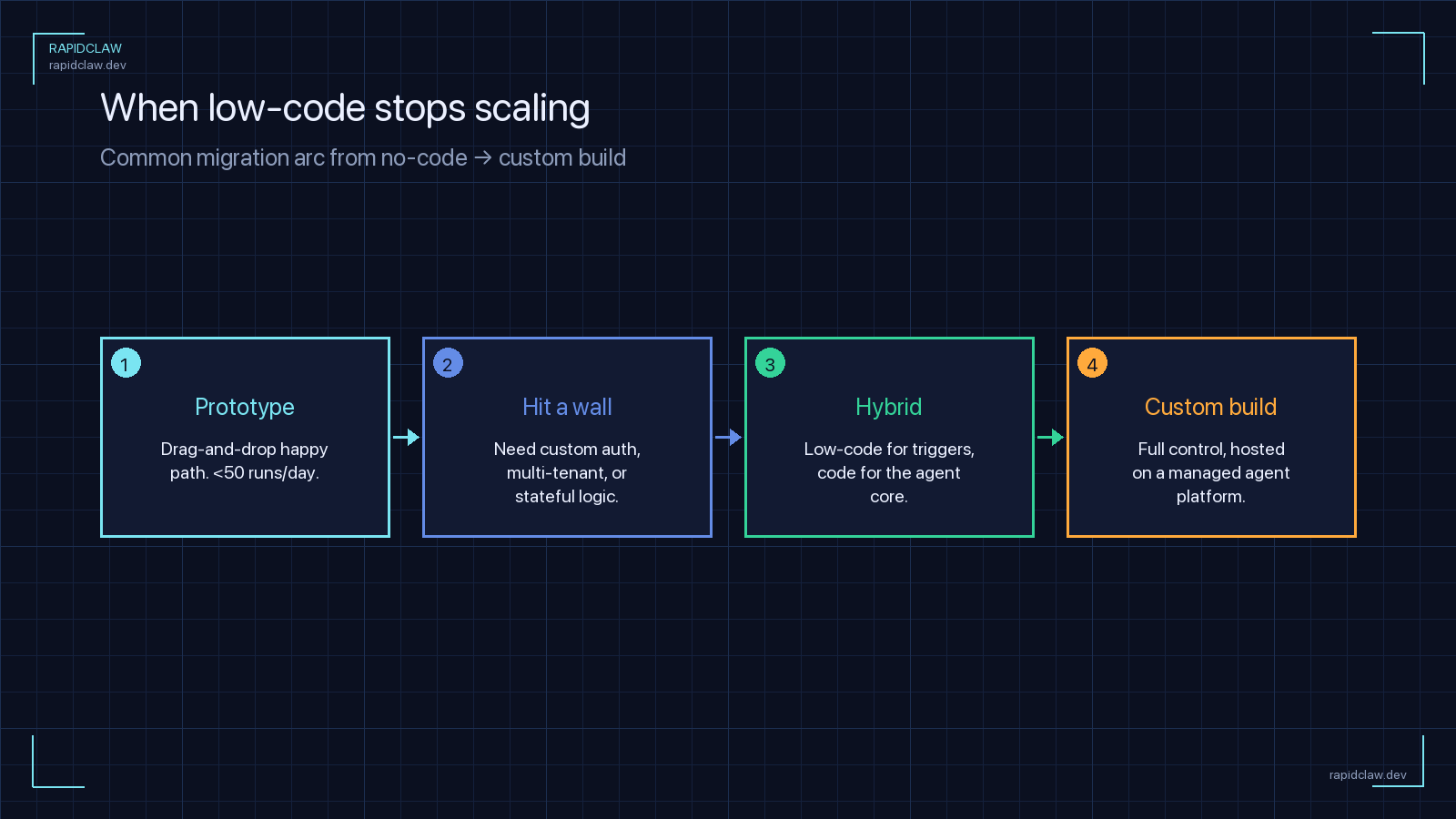
Pick low-code when the cost of a suboptimal agent is low and the cost of a developer’s time is high. Concretely, the green-flag scenarios are:
Internal tools and ops automations
Slack bots that answer “what’s our Q2 roadmap” from a Notion export, pipeline alerting that summarises incidents, approval flows that use an LLM to draft responses. Low throughput, internal users, easy-to-patch mistakes.
Content and marketing pipelines
Repurpose a blog post into social threads, generate first-draft email sequences, transcribe and tag podcast episodes. Humans are in the loop on the output; the LLM is a productivity multiplier, not a production dependency.
Rapid prototyping and validation
You have a hypothesis about an AI feature and want to test it with real users this week. A Dify chat app on a temporary subdomain is the fastest way to learn, even if you rebuild it later in code.
Augmenting an existing SaaS workflow
An n8n flow that enriches CRM leads with a GPT summary, or a Zapier-style step that auto-categorises support tickets. The AI is one node in a longer non-AI automation — that’s exactly what visual builders exist for.
A good heuristic: if you can describe the agent’s behaviour as a linear or tree-shaped workflow with fewer than ten decision points, low-code will beat code-first on build time and maintenance. Past that threshold, the tradeoffs flip.
When to Skip Low-Code Entirely
The breaking points
Visual runtimes work by wrapping LLM calls in a node graph. That abstraction is excellent for 80 % of agent workloads — and precisely wrong for the other 20 %. Here’s where it fails predictably:
1. Long-running, stateful multi-agent coordination
Agents that hand off to each other, maintain shared memory across hours or days, and resume from checkpoints are state machines. Flowise 2.0 added LangGraph nodes, but once you have more than three agents with branching state, the canvas becomes unreadable. Code-first frameworks like LangGraph, CrewAI, and Hermes Agent model this natively — see our AI Agent Framework Comparison 2026 for the deep dive.
2. Fine-grained latency and cost control
Low-code runtimes make a lot of decisions for you: when to cache, how to batch embeddings, which model to route to, how to parallelise tool calls. At low volume you don’t notice. At 100k+ requests a day, losing 200ms per call or mispricing a routing decision by $0.01 translates into real money. Code-first lets you profile, memoise, and route explicitly.
3. Evaluation, testing, and CI
You can’t pytest a Flowise canvas. Dify has built-in eval datasets — the best of the three — but it’s still a UI-driven flow, not something your GitHub Actions run on every PR. Agents that ship to customers need regression tests, and regression tests want code.
4. Heavy customisation and novel architectures
Memory systems that blend episodic and semantic stores. Custom tool-call protocols. Agents that control a browser or a desktop. The moment you need something the platform didn’t anticipate, you’re grafting HTTP nodes onto a canvas — which is worse than starting in code. If that sounds like your use case, look at Hermes Agent or OpenClaw.
Where Each Platform Breaks Down at Scale
Self-hosting a low-code platform is easy on day one and painful on day 400. Here are the specific failure modes teams hit most often.
n8n
- Single-tenant by design; multi-team setups need workarounds
- Queue mode required past ~200 concurrent executions (adds Redis + workers)
- No first-class agent state — memory lives in vector store nodes
- Upgrade path between major versions occasionally requires flow rewrites
Flowise
- Node-level concurrency is limited; long tool calls block the event loop
- Vector store and retriever nodes re-instantiate per call by default
- Multi-tenancy only in the paid cloud tier — self-host is single workspace
- LangChain version pinning means breaking changes land often
Dify
- Dataset indexing is synchronous; large doc uploads take minutes
- Workflow app execution is capped per plan; bursty traffic fails closed
- Plugin system is young — custom tools still require forking the repo
- Not optimised for sub-second chat latency (P95 often > 1.2s)None of these are deal-breakers for small teams. All of them become weekend-eating problems once you’re handling real traffic on a VPS you picked without knowing what you were getting into. That operational weight is what pushed us to build managed hosting in the first place — and it’s why our AI agent hosting guide spends so much time on boring topics like backups, autoscaling, and TLS rotation.
How Rapid Claw Supports Both Approaches
We built Rapid Claw for the reality that most teams don’t pick one camp. They start low-code, hit a ceiling on one particular agent, rebuild that piece in code, and end up running both in production. Our managed plane is designed for that mixed stack:
Deploy any framework behind one API
Bring your n8n, Flowise, or Dify docker-compose. Or bring LangGraph, CrewAI, OpenClaw, Hermes Agent, Paperclip, or a bespoke Python service. Each gets an isolated tenant VPC, TLS, autoscaling, and backups.
Mix low-code and code-first in one project
Route internal ops traffic to an n8n instance and customer-facing chat to a code-first LangGraph service. One dashboard, unified logs, shared secrets manager.
Migrate between them without lock-in
Prototype in Flowise, export the flow to LangChain code when it outgrows the canvas, redeploy on the same hostname. No DNS juggling, no new auth setup.
Observability and firewall built in
Structured tracing, token accounting, per-agent rate limits, and scoped API keys apply across every framework we host — low-code and code-first alike.
The opinionated take: low-code is a tool for the 80 % of agent work that doesn’t deserve a bespoke codebase, and code-first is a tool for the 20 % that does. A platform that forces you to pick one is solving the wrong problem. A platform that deploys either is solving the one you actually have.
A 60-Second Decision Framework
If you’re staring at this list of platforms and still unsure where to start, run through these four questions in order. Stop at the first one that answers your situation. For a category-level overview that puts low-code in context against managed and code-first options, see our AI agent platform breakdown.
Is the agent a single-step LLM call wrapped in a larger automation?
Use n8n. Its 400+ connectors and workflow-first design make it the fastest path to value.
Is the agent a customer-facing chat or RAG app over your documents?
Use Dify. The dataset-native RAG layer and built-in eval tooling are the best of the three for this shape.
Are you prototyping multi-step agent behaviour you plan to rebuild in code later?
Use Flowise. The clean ejection path to LangChain makes the prototype → production transition painless.
Do you need long-running multi-agent state, CI tests, or sub-second latency?
Skip low-code. Go straight to LangGraph, CrewAI, OpenClaw, or Hermes Agent — and deploy on a managed plane that handles the ops.
Frequently Asked Questions
Deploy any framework — low-code or code-first
Rapid Claw hosts n8n, Flowise, Dify, OpenClaw, Hermes Agent, LangGraph, CrewAI, and bespoke services on one managed plane. TLS, autoscaling, observability, and firewall controls included. Production-ready in under two minutes.
Start deployingRelated reading
Hermes vs CrewAI vs LangGraph vs AutoGen vs OpenClaw, across 10 dimensions
AI Agent Hosting: The Complete GuideSelf-hosted vs managed, architecture, cost breakdown, and common pitfalls
5 CrewAI Alternatives That Handle DeploymentFrameworks with real deployment stories, from managed to self-hosted
Why AI Agents Cost $100K/Year (And the Fix)The math behind agentic token consumption and smart routing
A2A Protocol: The Complete GuideWhen low-code platforms need to talk to each other, this is the wire
The AI Agent Marketplace, MappedWhere to publish — and source — agents built on these platforms
Paperclip AI Framework ExplainedThe pro-code framework behind a lot of newer low-code wrappers