Multi-Agent Orchestration Patterns: How to Coordinate 3+ AI Agents in Production

April 20, 2026·18 min read
One agent is a chatbot. Three agents working together is a system — and systems need patterns. This guide covers the five multi-agent orchestration patterns that actually hold up under production load: sequential, parallel, hierarchical, pub-sub, and blackboard. With framework code for CrewAI, LangGraph, and AutoGen — plus the state-management, error-handling, and deadlock traps that will bite you if you skip them.
TL;DR
There are five dominant multi-agent orchestration patterns: Sequential (pipeline), Parallel (fan-out/fan-in), Hierarchical (manager + workers), Pub-Sub (event-driven), and Blackboard (shared memory). Pick by coupling and latency: sequential for strict dependencies, parallel for independent subtasks, hierarchical for planning + execution, pub-sub for loose coupling, blackboard for open-ended problems. CrewAI, LangGraph, and AutoGen each support several patterns but lean into one. The real fight is state, retries, and deadlock — not which framework you chose.
Deploy multi-agent systems without the plumbing?
Try Rapid Claw free — 5 msgs, then $29/mWhy Orchestration Patterns Matter
A single LLM call is a function. Two agents passing messages is a protocol. Three or more agents coordinating toward a goal is a distributed system — and distributed systems fail in ways that single agents never do: partial failures, stale state, ordering bugs, and deadlock.
The good news: multi-agent systems don’t need new CS. The orchestration patterns that work for microservices, actor systems, and workflow engines work here too — you just have to pick the right one for your problem. Picking wrong means latency you can’t meet, cost you can’t afford, or race conditions you can’t reproduce.
This guide covers the five patterns that show up repeatedly in production agent systems, when to use each, what CrewAI, LangGraph, and AutoGen give you, and the failure modes to watch for.
Pattern 1: Sequential (Pipeline)
Shape
Agent A → Agent B → Agent C. Output of one is input to the next. No branching, no parallelism. Think Unix pipes with LLMs.
When to use it
- Each step has a hard dependency on the output of the previous step.
- You can tolerate the cumulative latency (N agents ≈ N round trips).
- You want the simplest system that could possibly work — sequential is the baseline every other pattern deviates from.
Real-world example
A content-production pipeline: a researcher gathers sources, a writer drafts the article, and an editor revises it. You cannot parallelize — the writer needs the researcher’s sources; the editor needs the writer’s draft.
from crewai import Agent, Task, Crew, Process
researcher = Agent(
role="Research Analyst",
goal="Find 5 authoritative sources on {topic}",
backstory="Meticulous, citation-focused.",
)
writer = Agent(
role="Technical Writer",
goal="Draft a 1500-word article from the research",
backstory="Clear, concrete, no filler.",
)
editor = Agent(
role="Senior Editor",
goal="Revise the draft for clarity and accuracy",
backstory="Ruthless line-editor.",
)
research_task = Task(description="Research {topic}", agent=researcher)
write_task = Task(description="Write the article", agent=writer,
context=[research_task]) # depends on research
edit_task = Task(description="Edit the draft", agent=editor,
context=[write_task]) # depends on writer
crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, write_task, edit_task],
process=Process.sequential, # <-- the pattern
)
result = crew.kickoff(inputs={"topic": "multi-agent orchestration"})Failure modes
- Cumulative latency: if each agent takes 30s, 5 agents = 2.5 minutes best case.
- Error propagation: a bad output at step 2 corrupts steps 3 through N. Validate between stages.
- No partial progress: if step 4 fails, you’ve already paid for 1–3. Checkpoint outputs to disk.
Pattern 2: Parallel (Fan-Out / Fan-In)
Shape
One dispatcher splits the task into N independent subtasks, N worker agents run concurrently, an aggregator combines their results.
When to use it
- The problem decomposes into independent subtasks (no cross-subtask dependencies).
- Latency matters — you need wall-clock time close to the slowest worker, not the sum.
- You’re willing to spend more on tokens for a faster result.
Real-world example
Competitive research: analyze 10 competitors simultaneously. Each worker agent handles one competitor; the aggregator produces a comparison matrix. Sequential would take 10x longer for no correctness benefit.
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class State(TypedDict):
competitors: list[str]
# Reducer: list concatenation across parallel branches
analyses: Annotated[list[dict], operator.add]
report: str
def dispatch(state): return state # pass-through
def analyze_competitor(state, competitor: str):
# Each branch runs one agent analysis
return {"analyses": [{"competitor": competitor, "summary": run_agent(competitor)}]}
def aggregate(state):
report = build_comparison_matrix(state["analyses"])
return {"report": report}
graph = StateGraph(State)
graph.add_node("dispatch", dispatch)
graph.add_node("aggregate", aggregate)
# Conditional fan-out: one branch per competitor
def fan_out(state):
return [("analyze", c) for c in state["competitors"]]
graph.add_conditional_edges("dispatch", fan_out)
for i in range(10): # pre-register worker nodes
graph.add_node(f"analyze_{i}", lambda s, i=i:
analyze_competitor(s, s["competitors"][i]))
graph.add_edge(f"analyze_{i}", "aggregate")
graph.set_entry_point("dispatch")
graph.add_edge("aggregate", END)
app = graph.compile()Failure modes
- Straggler problem: one slow worker blocks aggregation. Use a deadline; if a worker misses it, aggregate without it.
- Cost blow-up: fan-out N-way multiplies token spend by N. Cap concurrency.
- Rate-limit storms: 50 workers hitting the same LLM provider = 429s. Add a rate-limit queue in front of the provider.
Pattern 3: Hierarchical (Manager + Workers)
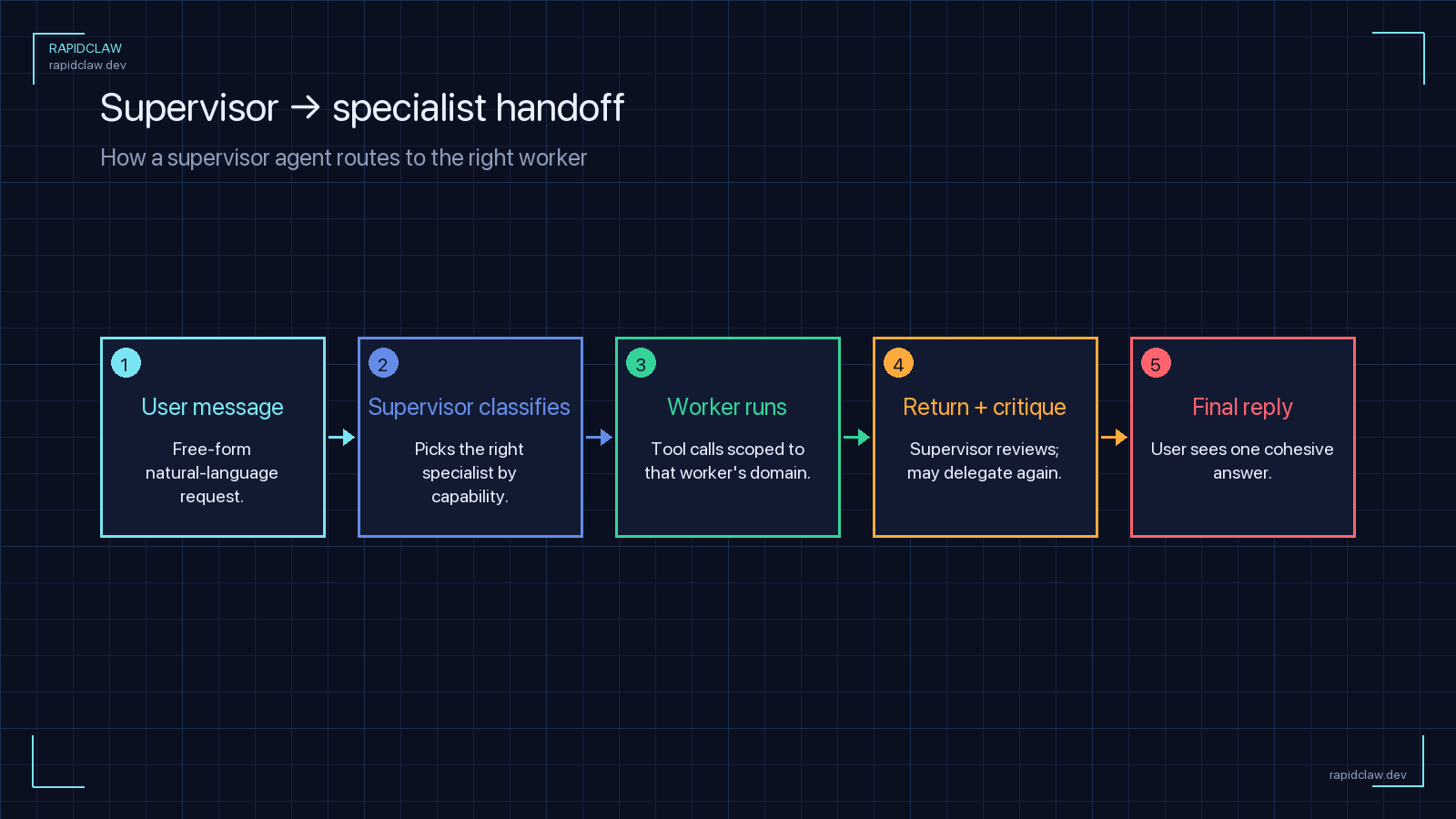
Shape
A manager agent decomposes the goal, delegates subtasks to specialist worker agents, reviews their output, and iterates. Planning and execution are separated roles.
When to use it
- The task requires dynamic planning — you can’t hard-code the sequence of steps ahead of time.
- Workers are specialists (one for code, one for data, one for writing), and the manager needs to route subtasks by capability.
- You need the manager to verify worker output and re-assign if quality is poor.
Real-world example
A software-engineering assistant: the manager reads a feature request, decides what’s needed (code + tests + docs), delegates each to a specialist agent, reviews the results, and loops back if anything fails a review. This is how Devin, OpenHands, and similar coding agents are structured.
from autogen import ConversableAgent, GroupChat, GroupChatManager
coder = ConversableAgent(
name="coder",
system_message="You write production Python. Return only code blocks.",
llm_config={"model": "claude-opus-4-7"},
)
tester = ConversableAgent(
name="tester",
system_message="You write pytest tests. Return only code blocks.",
llm_config={"model": "claude-sonnet-4-6"},
)
doc_writer = ConversableAgent(
name="doc_writer",
system_message="You write concise API docs in Markdown.",
llm_config={"model": "claude-sonnet-4-6"},
)
manager_agent = ConversableAgent(
name="manager",
system_message=(
"You are a tech lead. Decompose the feature into code, tests, and docs. "
"Delegate to coder/tester/doc_writer. Review each output and reject "
"anything that's not production-quality."
),
llm_config={"model": "claude-opus-4-7"},
)
group = GroupChat(
agents=[manager_agent, coder, tester, doc_writer],
messages=[],
max_round=20,
speaker_selection_method="auto", # manager decides who speaks next
)
chat_manager = GroupChatManager(groupchat=group,
llm_config={"model": "claude-opus-4-7"})
manager_agent.initiate_chat(
chat_manager,
message="Add a rate-limit decorator to our Python SDK.",
)Failure modes
- Infinite review loops: the manager rejects outputs indefinitely. Hard-cap rounds and fall back to “good enough.”
- Token spend: manager reads every worker’s full output. Summarize worker responses before feeding them back.
- Manager hallucinates capabilities: delegates to a worker that can’t actually do the task. Give the manager a structured tool schema of what each worker offers, not a free-text description.
Pattern 4: Pub-Sub (Event-Driven)
Shape
Agents don’t call each other directly. They publish events to topics, and any agent subscribed to that topic reacts. Loose coupling, no central coordinator.
When to use it
- You have many agents with many-to-many relationships, and hard-coding the graph is brittle.
- New agents need to be added or removed without rewiring existing agents.
- You want durable event logs for replay, audit, or debugging.
Real-world example
A customer-support system: when a ticket arrives, a classifier publishes a ticket.classified event. A billing-agent, tech-support-agent, and escalation-agent each subscribe with filters. Only the relevant one reacts. Adding a new agent type = adding a new subscriber; no existing code changes.
# Redis Streams as the event backbone — works with any framework
import redis, json, asyncio
r = redis.asyncio.Redis()
async def publish(topic: str, event: dict):
await r.xadd(topic, {"payload": json.dumps(event)})
async def subscribe(topic: str, group: str, consumer: str, handler):
await r.xgroup_create(topic, group, id="0", mkstream=True)
while True:
msgs = await r.xreadgroup(group, consumer, {topic: ">"},
count=10, block=5000)
for _, entries in msgs or []:
for msg_id, fields in entries:
event = json.loads(fields[b"payload"])
try:
await handler(event)
await r.xack(topic, group, msg_id)
except Exception as e:
# Retry up to N times, then dead-letter
log_error(msg_id, e)
# Classifier agent publishes
async def classifier_agent(ticket):
category = await llm_classify(ticket)
await publish("ticket.classified",
{"ticket_id": ticket.id, "category": category})
# Billing agent subscribes — only acts on billing tickets
async def billing_handler(event):
if event["category"] != "billing":
return
await llm_handle_billing(event["ticket_id"])
asyncio.gather(
subscribe("ticket.classified", "billing-group", "billing-1", billing_handler),
subscribe("ticket.classified", "tech-group", "tech-1", tech_handler),
subscribe("ticket.classified", "esc-group", "esc-1", escalation_handler),
)Failure modes
- Event storms: one agent’s event triggers another’s, which triggers three more, which triggers twelve. Add a trace ID and cap event chain depth.
- Observability collapse: without distributed tracing you cannot debug anything. Propagate a correlation ID through every event.
- Eventual consistency: an agent may react to a stale event. Include a version in the event and have subscribers ignore versions older than their last processed state.
Pattern 5: Blackboard (Shared Memory)
Shape
A shared workspace (the “blackboard”) holds the current problem state. Agents watch the board and contribute when they see an opportunity. A controller decides who writes next.
When to use it
- The problem is open-ended and you don’t know in advance which agents should contribute or in what order.
- Each agent can read the full context but only a subset can meaningfully add to it at any point.
- You’re doing emergent problem-solving — planning, hypothesis generation, creative synthesis.
Real-world example
Medical differential diagnosis: a shared board holds patient symptoms, test results, and current hypotheses. A symptom-reasoner, imaging-interpreter, lab-interpreter, and literature-searcher each watch the board. When new info arrives, whichever agent has something relevant to add contributes. No pre-defined order.
from dataclasses import dataclass, field
from typing import Callable
@dataclass
class Blackboard:
state: dict = field(default_factory=dict)
history: list = field(default_factory=list)
def read(self) -> dict:
return dict(self.state)
def write(self, agent: str, key: str, value):
self.state[key] = value
self.history.append({"agent": agent, "key": key, "value": value})
@dataclass
class KnowledgeSource:
name: str
precondition: Callable[[dict], bool] # when is this agent applicable?
action: Callable[[dict], dict] # what does it contribute?
class Controller:
def __init__(self, bb: Blackboard, sources: list[KnowledgeSource]):
self.bb = bb
self.sources = sources
def step(self) -> bool:
# Find all agents whose precondition matches current state
applicable = [s for s in self.sources if s.precondition(self.bb.read())]
if not applicable:
return False # done — no one has anything to add
# Pick the highest-priority applicable agent (custom scoring)
chosen = max(applicable, key=lambda s: priority(s, self.bb.read()))
contribution = chosen.action(self.bb.read())
for k, v in contribution.items():
self.bb.write(chosen.name, k, v)
return True
def run(self, max_steps: int = 50):
for _ in range(max_steps):
if not self.step():
break
return self.bb.read()Failure modes
- Non-termination: no agent signals “done.” Add a confidence threshold or hard step cap.
- State bloat: the board grows faster than you can summarize it; every agent read becomes a 100K-token LLM call. Add a summarizer agent that compresses old entries.
- Write conflicts: two agents write to the same key simultaneously. Either serialize writes (simplest) or use optimistic concurrency with version stamps.
Pattern Decision Matrix

Most production systems aren’t a single pattern — they’re nested. A hierarchical manager dispatches sequential sub-pipelines; pub-sub drives an outer event loop with a blackboard inside each handler. Start with the simplest pattern that fits, and only add complexity when a specific pain point forces it.
| Pattern | Coupling | Latency | Best For |
|---|---|---|---|
| Sequential | Tight | Sum of steps | Linear pipelines with strict deps |
| Parallel | Tight | Max of steps | Independent subtasks, fan-out/in |
| Hierarchical | Medium | Variable | Dynamic planning, specialists |
| Pub-Sub | Loose | Async | Many-to-many, extensible systems |
| Blackboard | Loose | Iterative | Open-ended problem-solving |
Hybrids: Where Real Systems Live
In practice, production systems blend patterns. Three hybrids worth stealing:
- 1.Hierarchical-of-pipelines. A top-level manager dispatches to one of N pre-built sequential pipelines. Common in multi-tenant systems where each tenant has a different workflow but policy enforcement is centralized.
- 2.Pipeline with embedded pub-sub stage. Deterministic pipeline for ingest and publish; a pub-sub stage in the middle for the creative/research step where exploration matters. You get the fault tolerance of pipelines and the emergent quality of event-driven swarms.
- 3.Manager over a blackboard. A hierarchical manager sets up the blackboard, defines the termination condition, then reads the final shared state and writes a structured output. The blackboard does the thinking; the manager does the reporting.
Picking Agents: OpenClaw vs Hermes for Each Role
The pattern tells you the shape. Picking which framework fills each role is a separate decision. A rough heuristic after running both in production:
- OpenClaw →computer-use specialists: browsing, file system, desktop automation, anything requiring a screen. The role is “do things in the world.”
- Hermes →reasoning specialists: analysis, drafting, planning, critique, the manager role itself. The role is “think about things.”
- Either →API-tool agents (database, email, search). Pick whichever framework owns more of your existing code.
For a deeper framework comparison, see Hermes Agent vs OpenClaw. For cost implications of running a multi-agent setup, token cost math for agentic systems is a good follow-up — multi-agent amplifies token consumption, and without smart routing the bill scales quickly.
Framework Support: CrewAI vs LangGraph vs AutoGen
Every major framework supports multi-agent workflows, but they lean into different patterns. See our full 2026 framework comparison for the complete feature matrix; here’s the pattern-support summary.
CrewAI
First-class sequential and hierarchical. Parallel works via Process.parallel. Pub-sub and blackboard: roll your own.
Strength: ergonomic role-based API. Weakness: state flows through task outputs; no native event bus.
LangGraph
Graph-native. Any pattern expressible as nodes + edges works: sequential, parallel with reducers, hierarchical via subgraphs, pub-sub via conditional edges.
Strength: most flexible. Weakness: verbose; every pattern requires explicit graph construction.
AutoGen
Conversation-centric. Hierarchical via GroupChat, blackboard via a shared chat buffer. Sequential/parallel: custom.
Strength: best for chat-style agent collaboration. Weakness: harder to fit non-chat workflows.
Cross-Cutting Challenges
These problems exist in every pattern. Your framework gives you primitives — the policies are your job.
State management
State lives in three places: the LLM context window, the orchestrator’s working memory, and durable storage. Keep them in sync or you get stale-read bugs that only surface under load. See our memory & state guide for durable patterns. Three rules that hold regardless of pattern:
- The orchestrator’s state is the source of truth, not any individual agent’s context window.
- Checkpoint after every agent step; resume from the last checkpoint on failure.
- Version every state update. Optimistic concurrency beats locks for LLM workloads — the retry cost is usually a rounding error next to the LLM call itself.
Error handling & retries
LLM calls fail for three distinct reasons, and each needs a different retry strategy:
- Transient (429, 503, network): exponential backoff with jitter. Retry the same call.
- Content-quality (malformed JSON, constraint violation): don’t blindly retry — re-prompt with the error message as feedback. The model fixes its own output 90% of the time.
- Fatal (auth, quota): don’t retry. Dead-letter the task and page a human.
Whatever you do, cap total retries per task. An agent in a retry loop at machine speed can burn through a month’s budget in an afternoon.
Deadlock & livelock
Multi-agent systems deadlock in ways single agents can’t. Three common traps:
- Circular delegation: Agent A asks B, B asks C, C asks A. Add a hop counter; drop requests over threshold N.
- Mutual waiting: two agents each wait for the other’s output. Use timeouts on every inter-agent request; never block indefinitely.
- Livelock (no progress): manager rejects every worker output, worker keeps re-submitting. Bound rounds; after M rounds, accept the best attempt.
The meta-rule
Every inter-agent interaction needs a timeout, a retry cap, and a step counter. If you only add one thing to your orchestration code after reading this post, make it these three.
How Rapid Claw Manages Multi-Agent Deployments
The patterns above are framework-agnostic. Rapid Claw runs them all — but the part we take off your plate is the operational layer: deploying multiple agents together, keeping their state consistent, wiring up observability, and catching the cross-cutting failures described above before they cascade.
- Per-crew rate limits. Fan-out patterns are the #1 cause of runaway cost. Rapid Claw caps concurrent agent calls per crew and per tenant, so a misbehaving parallel dispatch can’t torch your budget.
- Shared state backend. Redis-backed blackboard and checkpointing out of the box — no need to run Redis yourself or roll your own state layer.
- Correlation IDs end-to-end. Every cross-agent call propagates a trace ID through logs and metrics. Debugging a 12-agent pub-sub failure is legible instead of archaeological.
- Deadlock guards. Global hop counters and per-task step caps are enforced at the orchestrator, not trusted to each agent’s prompt.
- Framework-neutral. If you’ve already built with CrewAI, LangGraph, or AutoGen, deploy as-is. See the hosting guide for the full architecture.
The short version
Pick the orchestration pattern that matches your problem. Build it in whichever framework you prefer. Ship it on Rapid Claw and skip the weeks of plumbing — state, observability, rate limits, and deadlock guards come with the platform.
Deploy multi-agent crews without the plumbing
CrewAI, LangGraph, AutoGen — bring your pattern of choice. Rapid Claw handles rate limits, shared state, observability, and deadlock guards for you.
Try Rapid Claw free — 5 msgs, then $29/mRelated reading
Hermes vs CrewAI vs LangGraph vs AutoGen vs OpenClaw
AI Agent Hosting: The Complete GuideArchitecture, cost, security, and pitfalls
AI Agent Memory & State ManagementContext windows, persistence, vector stores
AI Agent Observability GuideLogs, metrics, traces for self-hosted agents
Paperclip AI Framework for Developers44.9K stars in 3 weeks — what you need to know
A2A Protocol: The Complete GuideThe wire protocol for the orchestration patterns above
Multi-Model Agent CollaborationMix Claude, GPT, and Gemini agents inside one orchestrator